
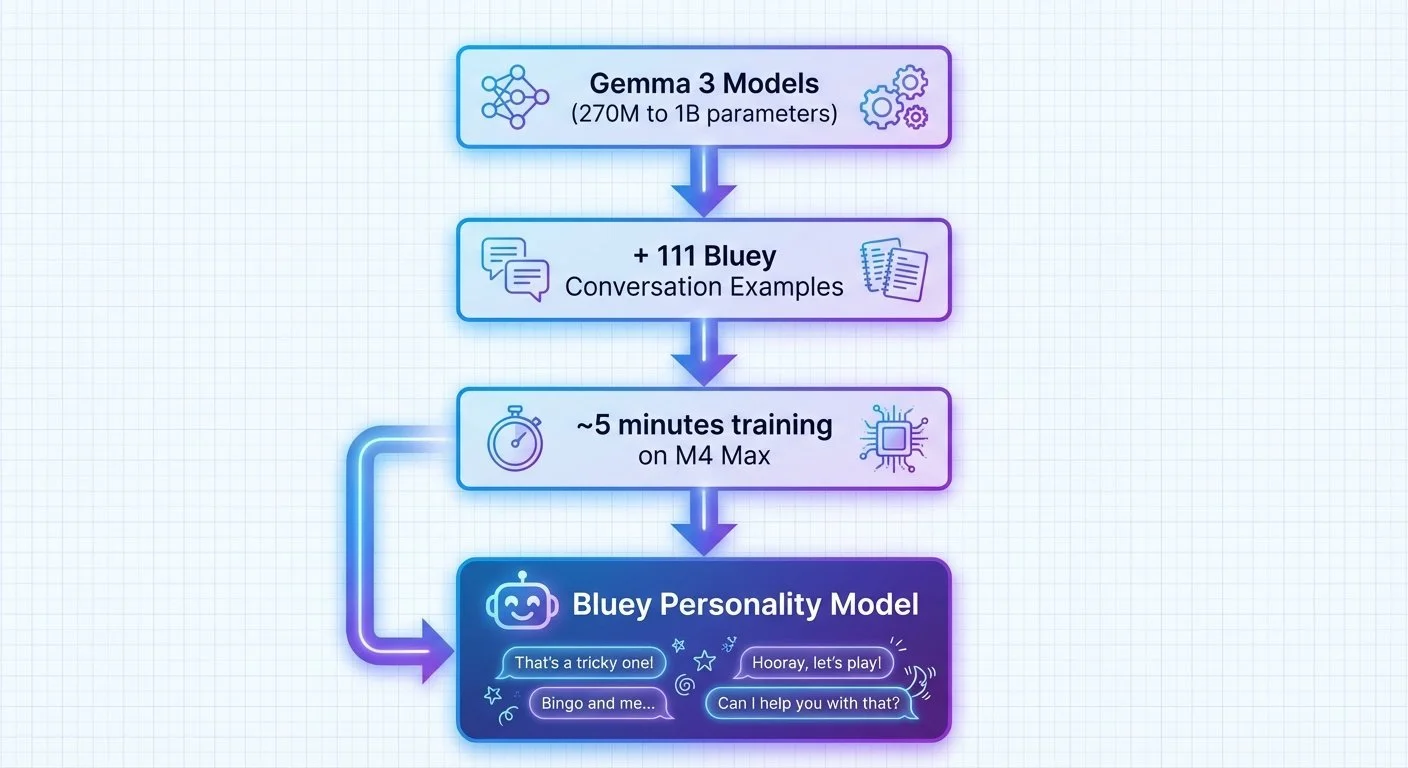
Fine-Tuning Gemma for Personality - Part 1: Why Fine-Tune a 6-Year-Old?
I taught an AI to talk like Bluey Heeler from the kids' show. Not through prompt engineering or RAG—through fine-tuning a small language model on 111 conversation examples. Five minutes of training on my MacBook. The model learned to mimic her speech patterns.
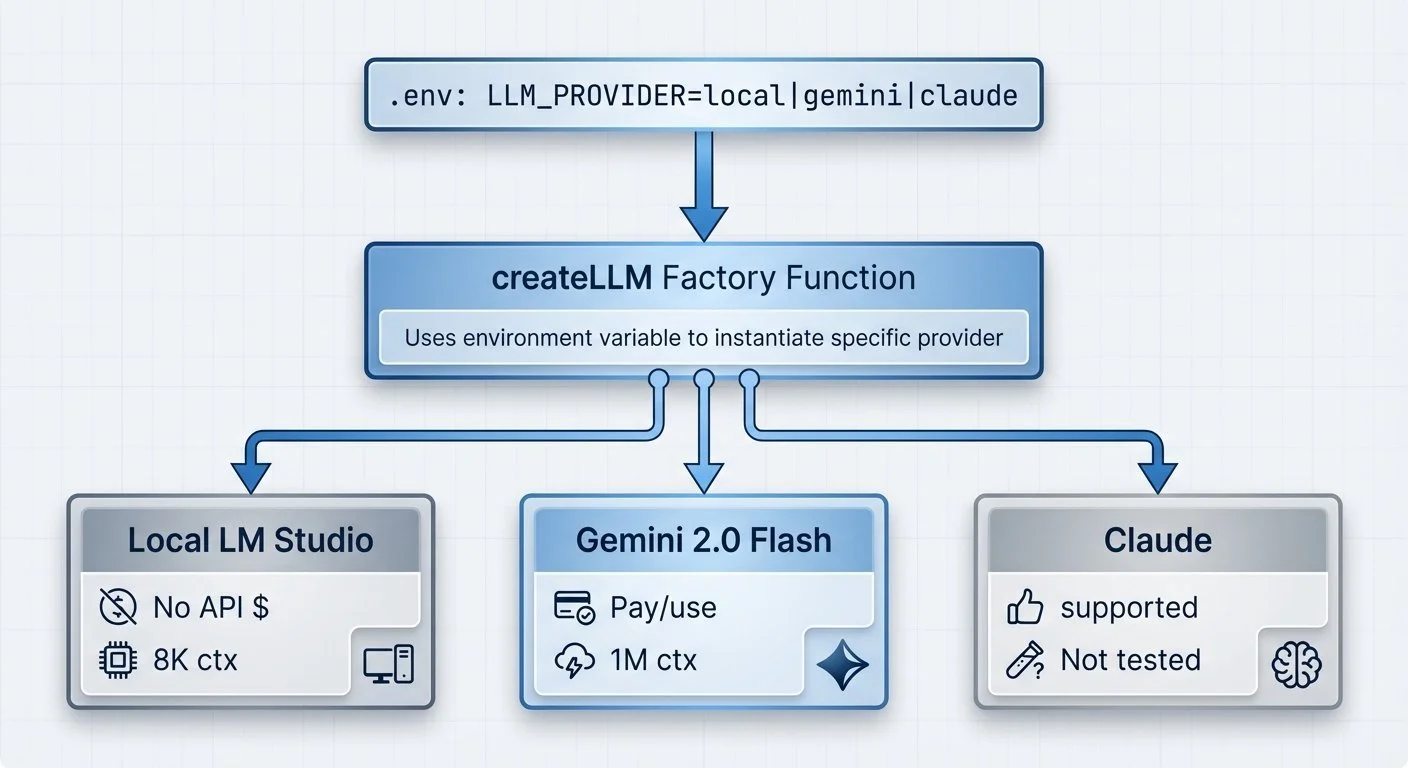
Building an Agentic Personal Trainer - Part 7: LLM Provider Abstraction
Running AI locally has no API costs—just electricity. Cloud providers charge per token. I wanted to switch between local and cloud models without rewriting my agent code.
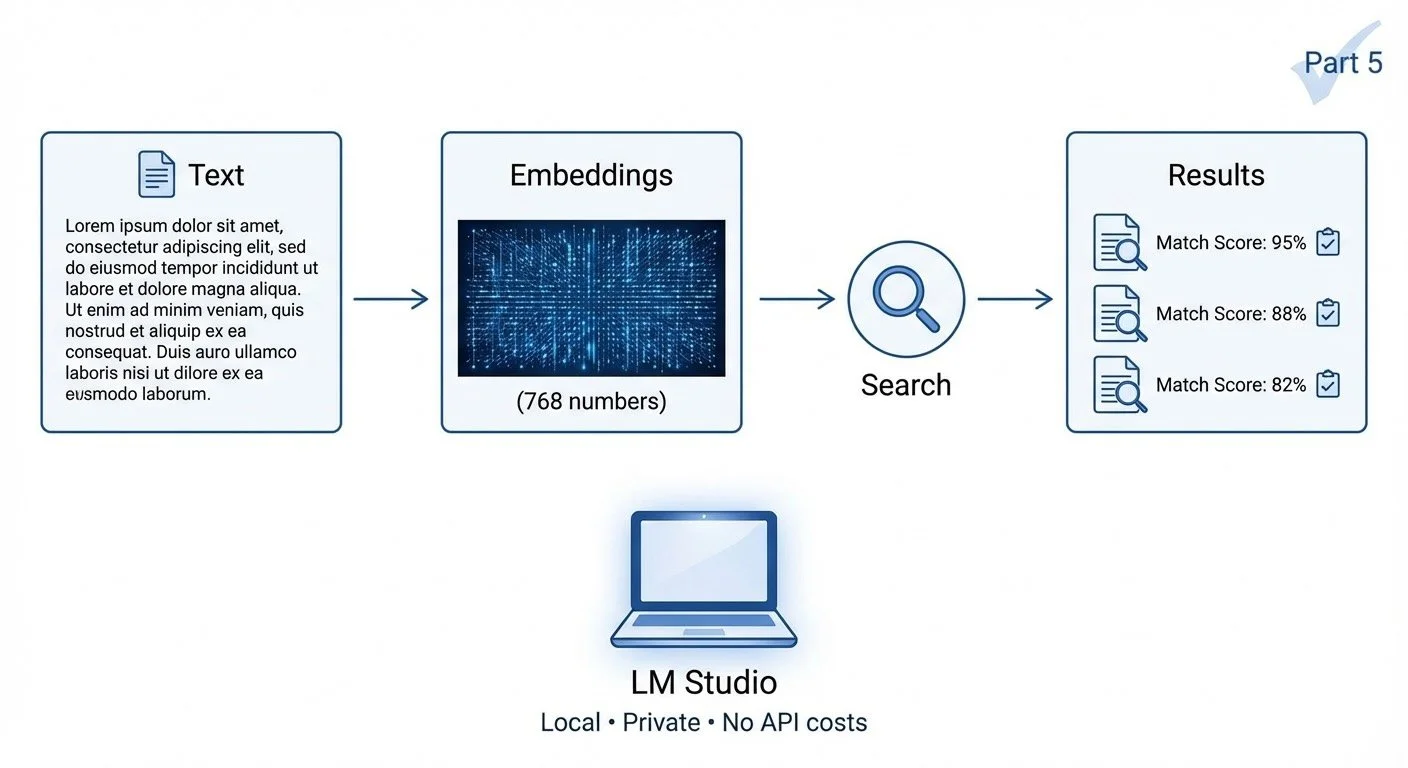
Building a Local Semantic Search Engine - Part 5: Learning by Building
Building a semantic search engine taught me more about embeddings than reading about them ever could. The real value wasn't the tool—it was understanding what those 768 numbers actually mean.

Building a Local Semantic Search Engine - Part 4: Caching for Speed
First search on a new directory: wait for every chunk to embed. A hundred chunks? A few seconds. A thousand? You're waiting—and burning electricity (or API dollars if you're using a cloud service). Second search: instant. The difference? A JSON file storing pre-computed vectors. Caching turned "wait for it" into "already done."
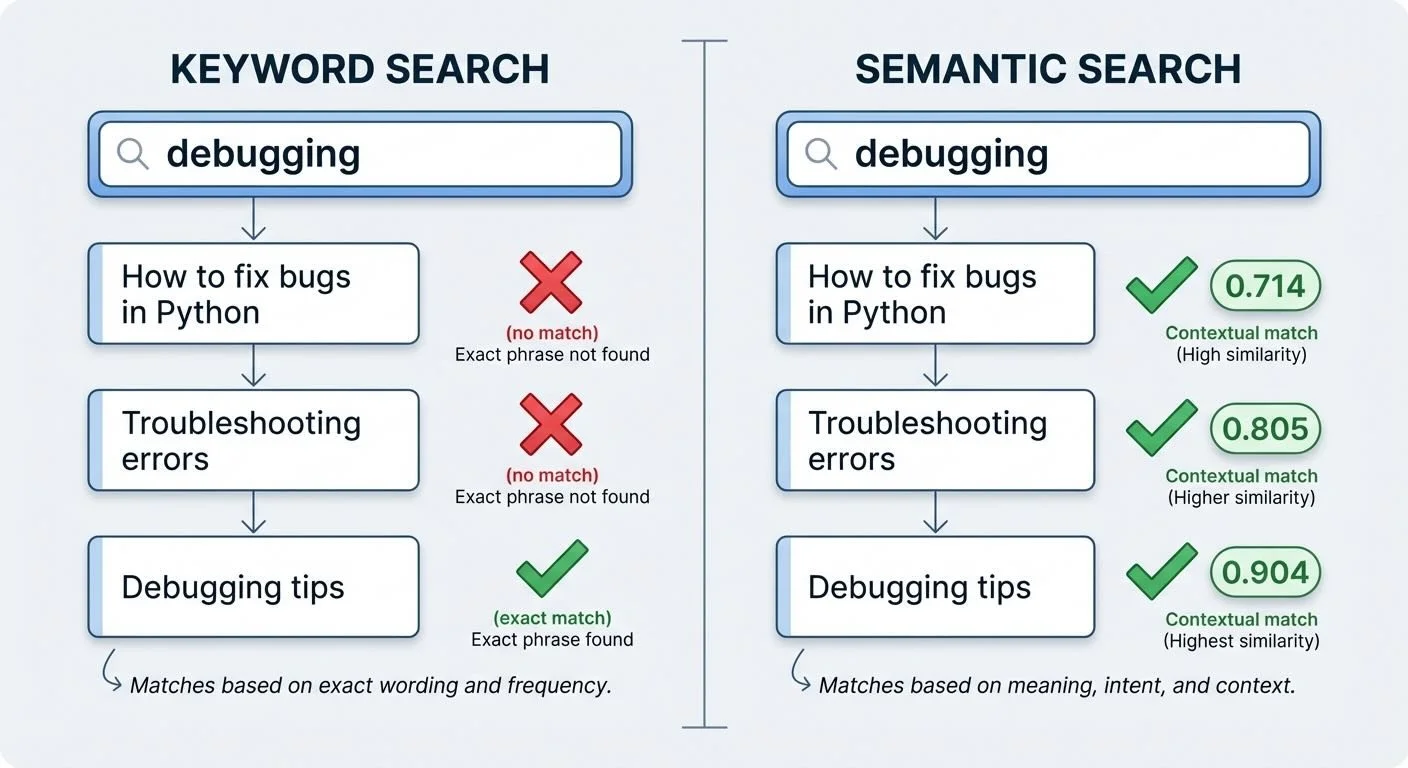
Building a Local Semantic Search Engine - Part 2: From Keywords to Meaning
Traditional search fails when you don't remember the exact words. Searching "debugging" won't find your notes about "fixing bugs." Semantic search finds them anyway—because it searches by meaning, not keywords.
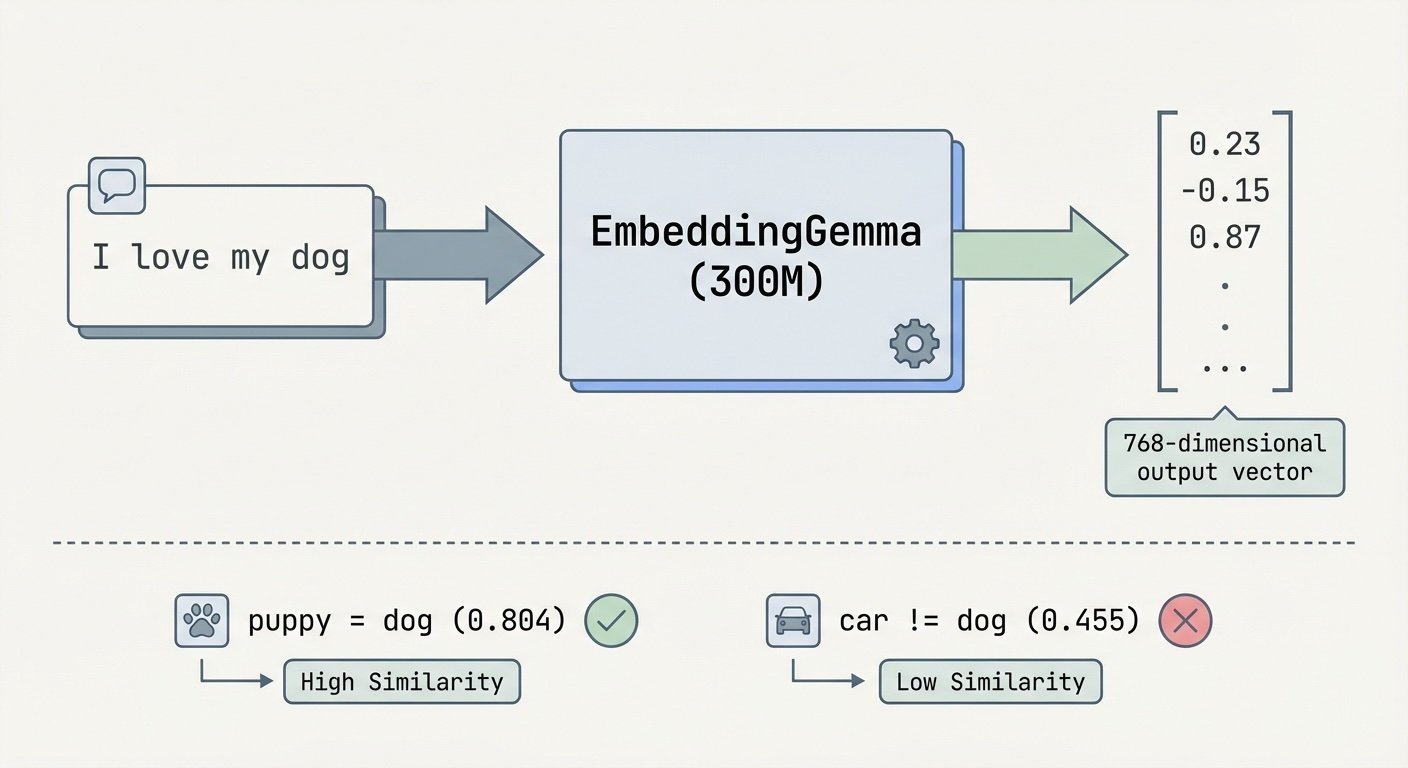
Building a Local Semantic Search Engine - Part 1: What Are Embeddings?
"I love playing with my dog" and "My puppy is so playful and fun" are 80.4% similar. Compare that to "Cars are expensive to maintain"—only 45.5% similar. How does a computer know that? Embeddings—and I wanted to run them entirely on my laptop.