
Fine-Tuning Gemma for Personality - Part 1: Why Fine-Tune a 6-Year-Old?
I taught an AI to talk like Bluey Heeler from the kids' show. Not through prompt engineering or RAG—through fine-tuning a small language model on 111 conversation examples. Five minutes of training on my MacBook. The model learned to mimic her speech patterns.
After building agents with LangChain and working with embeddings, I wanted to explore fine-tuning. But not for a practical task—for personality. Can you teach a small model to capture someone's conversational voice?
I chose Bluey because:
- Personal familiarity: My oldest daughter loved the show—I've watched many episodes
- Distinctive voice: Optimistic, enthusiastic, Australian kid speech patterns
- Clear personality: Empathetic 6-year-old with consistent character traits
- Well-defined character: Easy to generate consistent training examples
- Fun constraint: If it works for a cartoon dog, it could work for other use cases
The experiment: fine-tune Google's Gemma 3 models on Apple Silicon using 111 conversation pairs. I tested multiple sizes (270M and 1B parameters) and types (base and instruction-tuned).
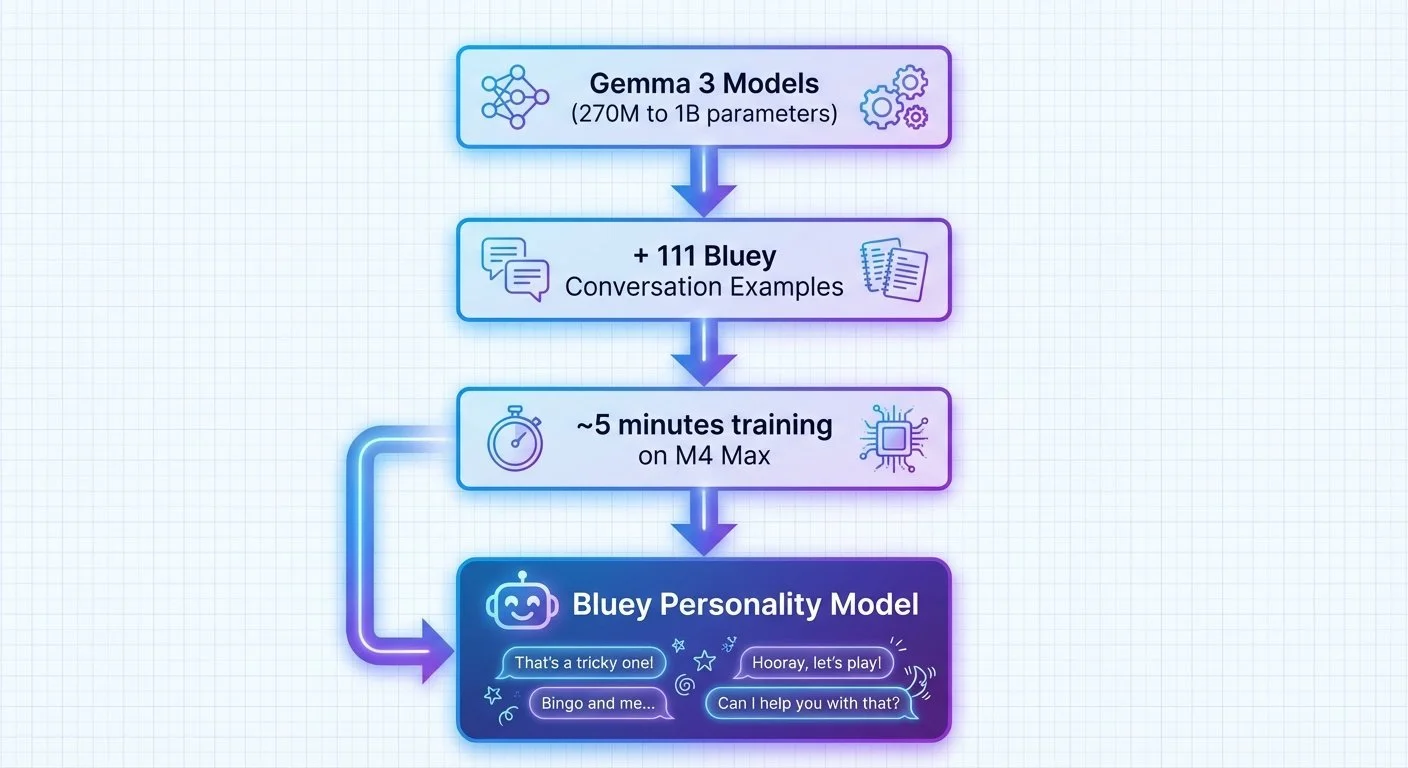
The Fine-Tuning Goal: Flow diagram showing Gemma 3 models being trained with 111 Bluey conversation examples
Why personality over tasks?
Most fine-tuning tutorials focus on specific tasks: classification, Q&A, code generation. Personality is harder. You're not teaching the model what to say—you're teaching it how to say things. The difference between "I can help with that" and "Yeah! I can help! What kind of homework is it?"
That subjective evaluation requires iteration. Lots of it. Which is why I ran this locally on Apple Silicon (M4 Max with 128GB RAM) instead of cloud notebooks. No time limits when Colab disconnects. No API costs adding up. Training data stays private. Just fast, cheap iteration on a problem where "does this sound like Bluey?" takes multiple attempts to get right.
Fine-tuning for personality is a different challenge than task-specific training. You can't measure success with accuracy metrics. The question isn't "did it get the right answer?"—it's "does this sound like Bluey?"
That subjective evaluation makes this both harder and more interesting. Next: how I built the training dataset from 111 conversations.
Part 1 of 8 in the Fine-Tuning Gemma for Personality series.
gemma-local-finetune - View on GitHub
This post is part of my AI journey blog at Mosaic Mesh AI. Building in public, learning in public, sharing the messy middle of AI development.