

The Bart Test - Part 9: The Question I Couldn't Answer
After questioning whether the Bart Test was worth continuing, I finally got the Experiment 05 evaluation sheets back.
I glanced at the scores and saw lots of 8s, 9s, and 10s.
My first reaction wasn't excitement. It was concern.
The Bart Test - Part 6: The American Ninja Warrior Problem
The process validation from [Part 5](/blog/bart-test-part-5-redesigning-from-scratch) worked. Judges completed the paper sheets in about 10 minutes. They engaged with it. I got detailed feedback.
When I sat down to analyze the [completed ratings](https://github.com/bart-mosaicmeshai/bart-test/blob/main/evaluation_sheets/20251228/completed_ratings_20251228.json) from Experiment 04, the patterns were clear. But I realized I was at risk of misinterpreting what they meant.

Fine-Tuning Gemma for Personality - Part 6: Testing Personality (Not Just Accuracy)
How do you test if an AI sounds like a personified 6-year-old dog? You can't unit test personality. There's no accuracy metric for "sounds like Bluey."

Fine-Tuning Gemma for Personality - Part 5: Base Models vs Instruction-Tuned
Same training data. Same hardware. Same 5 minutes. I tested both base (-pt) and instruction-tuned (-it) models to see if one would handle personality better. Both struggled with consistency.
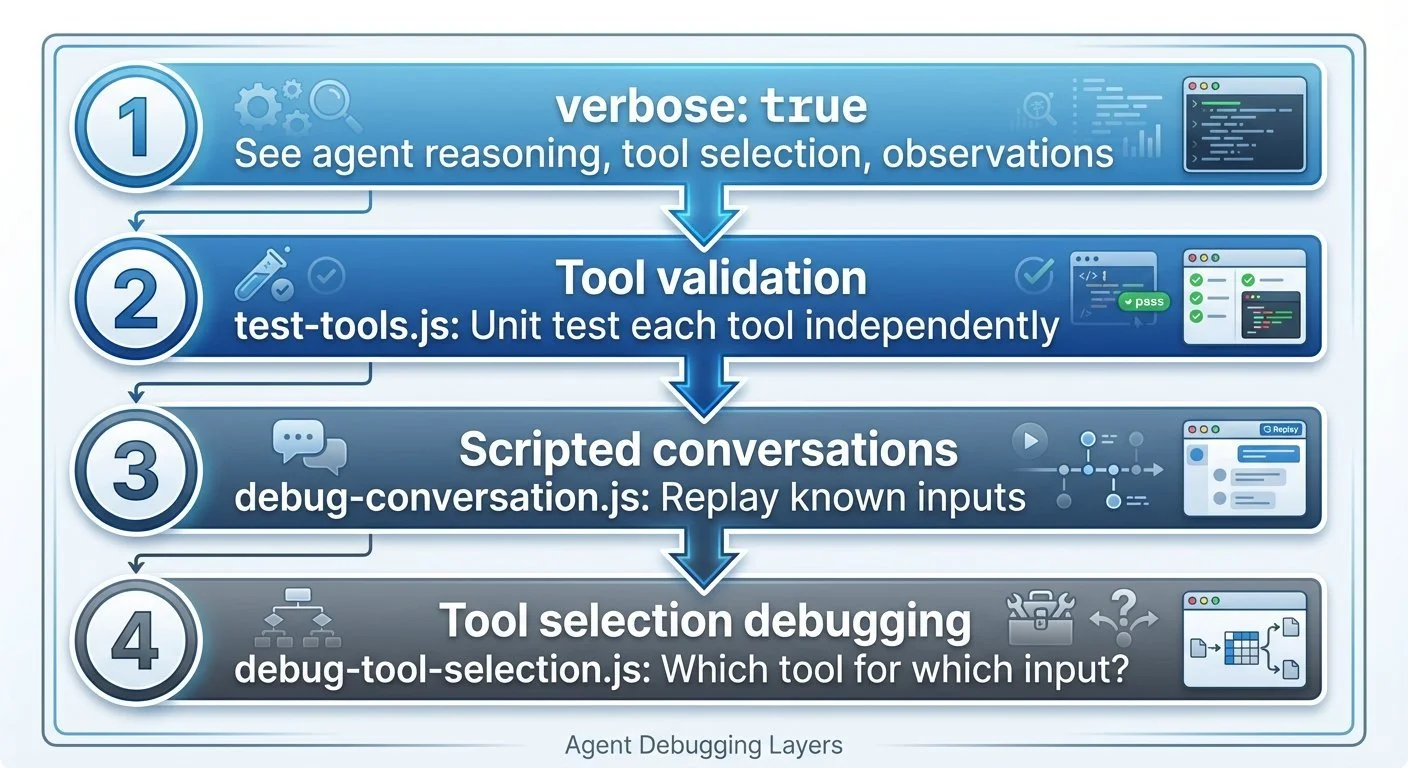
Building an Agentic Personal Trainer - Part 8: Testing and Debugging Agents
How do you test an AI agent? Unit tests don't cover "it gave bad advice." Verbose mode became my best debugging tool—watching the agent think out loud.

Building a Local Semantic Search Engine - Part 4: Caching for Speed
First search on a new directory: wait for every chunk to embed. A hundred chunks? A few seconds. A thousand? You're waiting—and burning electricity (or API dollars if you're using a cloud service). Second search: instant. The difference? A JSON file storing pre-computed vectors. Caching turned "wait for it" into "already done."