
Building a Local Semantic Search Engine - Part 1: What Are Embeddings?
"I love playing with my dog" and "My puppy is so playful and fun" are 80.4% similar. Compare that to "Cars are expensive to maintain"—only 45.5% similar. How does a computer know that? Embeddings—and I wanted to run them entirely on my laptop.
Embeddings convert text into numbers that capture meaning. The idea: place every word or phrase as a point in a 768-dimensional space, where similar concepts end up near each other. "Dog" and "puppy" land close together; "dog" and "refrigerator" land far apart. The "meaning" is encoded in the position—and we measure similarity by calculating the distance (or angle) between points. (For a deeper dive, see Google's embeddings crash course.)

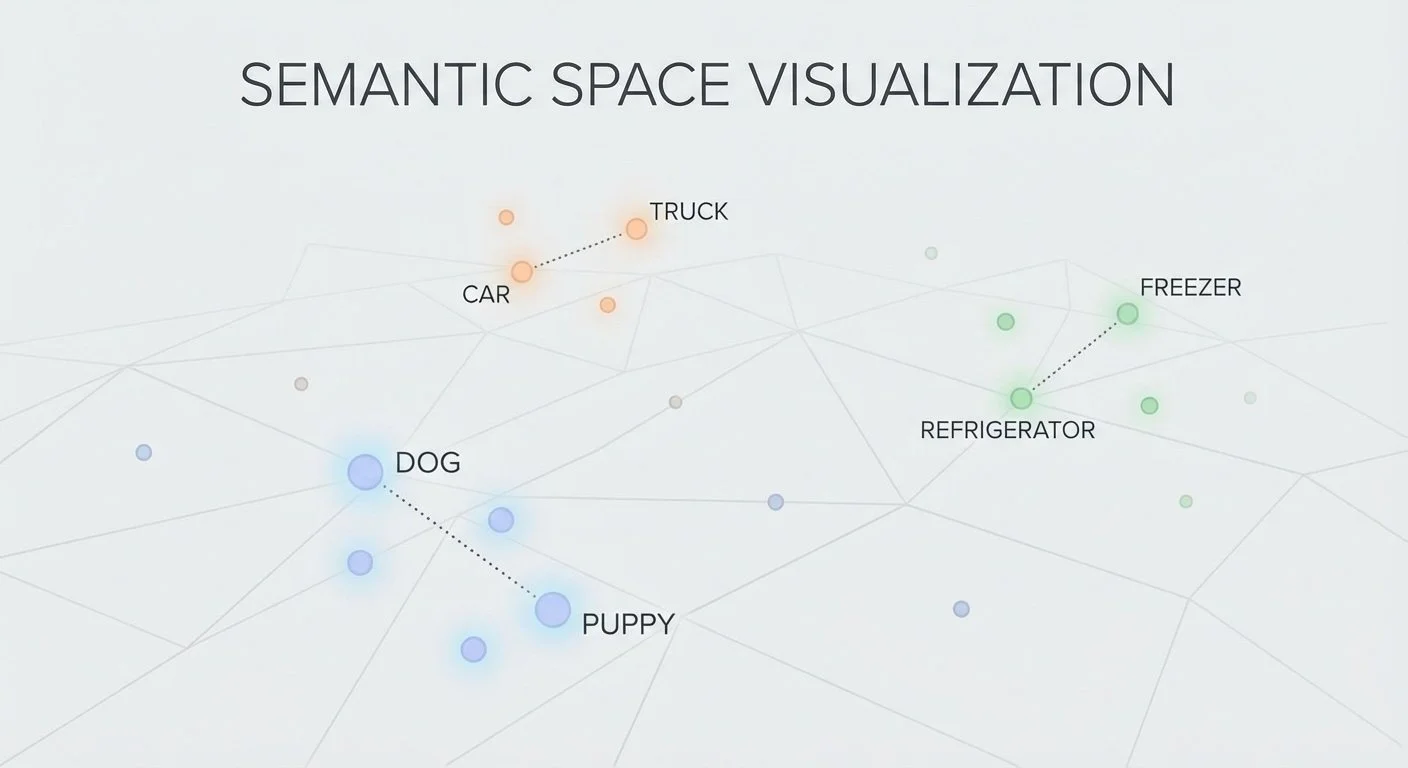
Semantic space visualization: Similar concepts cluster together in semantic space
Google's EmbeddingGemma model takes any text and outputs those 768 numbers—a vector representing that text's location in this semantic space.
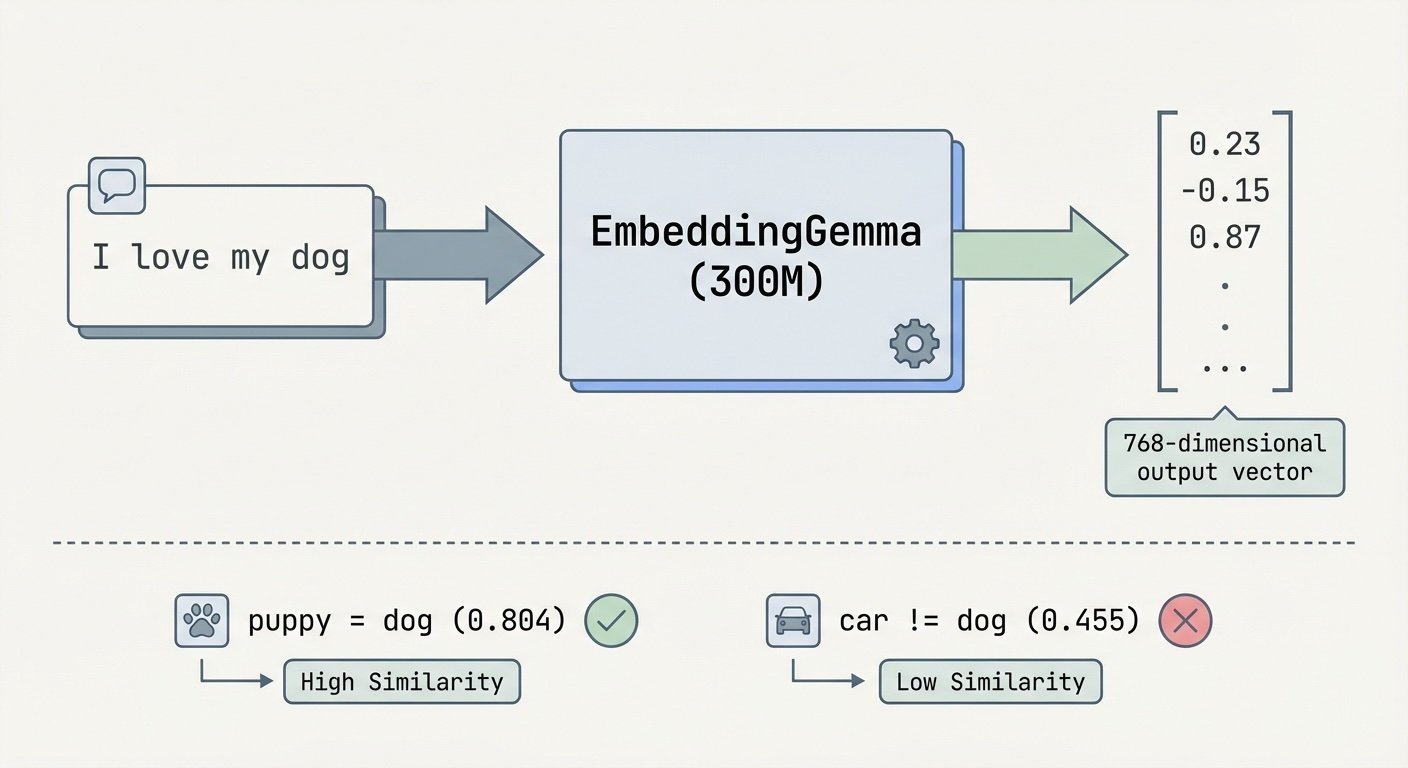
Text to embedding flowchart: Text becomes 768 numbers that capture semantic meaning
I set up EmbeddingGemma through LM Studio—a desktop app that runs models locally. The code is simple (demo_lmstudio.py:17-23):
from openai import OpenAI
client = OpenAI(base_url="http://localhost:1234/v1", api_key="not-needed")
def get_embedding(text):
response = client.embeddings.create(input=text, model="embedding")
return response.data[0].embedding # 768 numbersLM Studio exposes an OpenAI-compatible API locally. No internet, no API keys, no per-request costs. The model runs in under 200MB of RAM.
Why local? Three reasons:
- Privacy: My documents never leave my machine
- Cost: Zero per-query fees (embedding APIs charge per token)
- Speed: Sub-second inference, no network latency
I tested with simple comparisons by running demo_lmstudio.py:
source venv/bin/activate
python demo_lmstudio.py"I love playing with my dog" vs "My puppy is so playful and fun" scored 0.804—the model understands they're about the same thing despite different words. "The weather is nice today" scored 0.494 against the dog sentence, and "Cars are expensive to maintain" scored 0.455. Unrelated topics, lower similarity.
Embeddings feel like magic until you see them work. The numbers themselves are meaningless—it's the relationships between vectors that matter. Two texts about dogs end up near each other in 768-dimensional space. That's semantic search in a nutshell.
Next: turning these similarity scores into an actual search engine.
Part 1 of 5 in the EmbeddingGemma series.
embeddinggemma - View on GitHub
This post is part of my daily AI journey blog at Mosaic Mesh AI. Building in public, learning in public, sharing the messy middle of AI development.