
Building a Local Semantic Search Engine - Part 5: Learning by Building
This is Part 5 of a series on building a local semantic search engine. Read Part 1 for embeddings, Part 2 for semantic search, Part 3 for indexing, and Part 4 for caching.
Building a semantic search engine taught me more about embeddings than reading about them ever could. The real value wasn't the tool—it was understanding what those 768 numbers actually mean.
This series covered the full stack of a local semantic search engine:
- Part 1: Embeddings convert text to 768-dimensional vectors where similar concepts cluster together
- Part 2: Cosine similarity measures how "alike" two vectors are (0.80+ very similar, 0.60+ good match, 0.40+ weak)
- Part 3: Chunking splits large files so search results point to specific sections, not just files
- Part 4: Caching avoids regenerating embeddings on every search
The entire system runs locally via LM Studio—no API costs, no data leaving your machine, under 200MB of RAM.
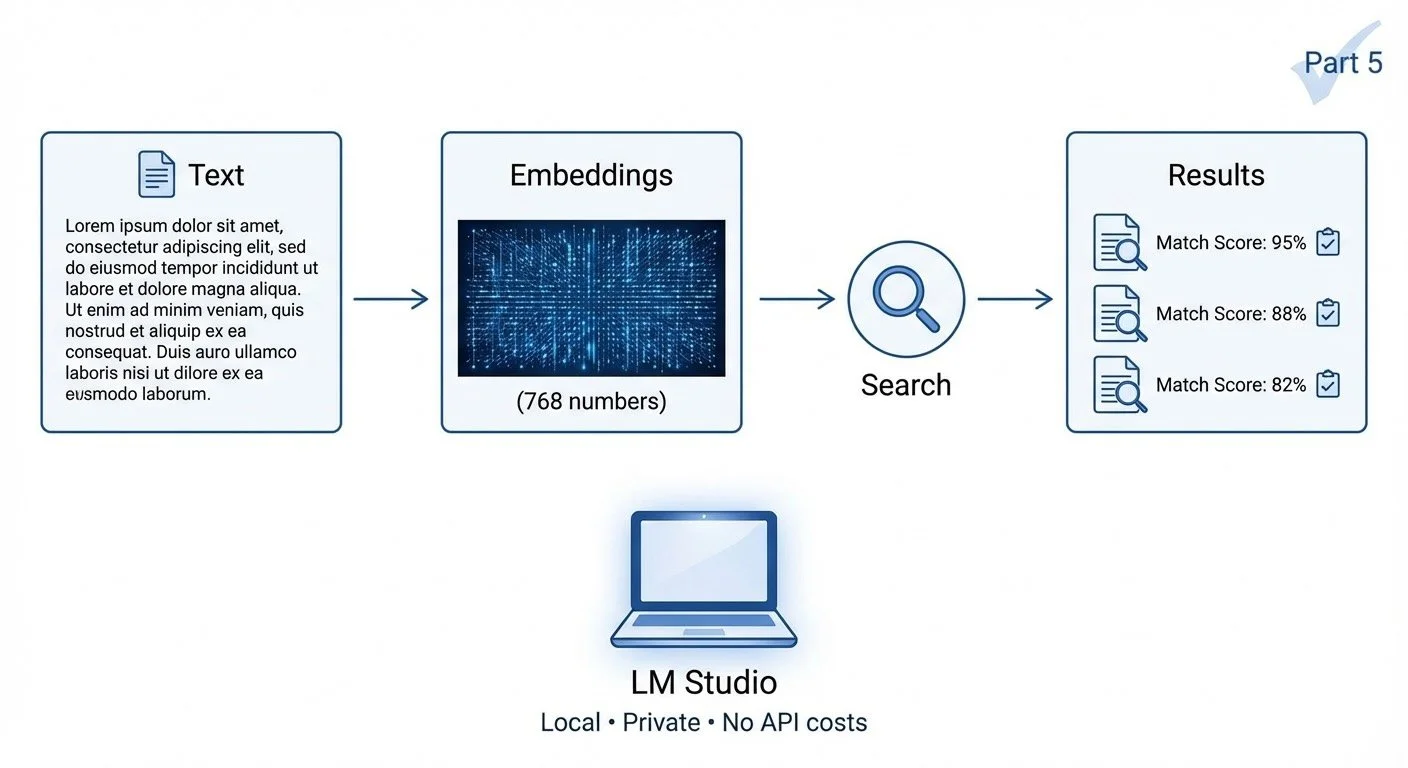
Series recap: From text to vectors to search—all running locally
Potential next steps for this project:
- Personal knowledge RAG: Feed search results to an LLM for Q&A over documents
- Code similarity finder: Find duplicate or related functions across repositories
- Document clustering: Auto-organize files by topic using embedding distances
This was an experiment in learning by building. I didn't set out to create a production tool—I wanted to understand how embeddings work by implementing them end-to-end. That goal was achieved.
The code is simple, the approach is basic, and there's plenty that could be improved. But now when I read about vector databases, RAG systems, or embedding models, I have a mental model to hang that knowledge on. That's the real output.
Local-first AI is more practical than I expected. A 300M parameter model running offline, with no API costs, in under 200MB of RAM. For experiments like this, that's the sweet spot.
Part 5 of 5 in the EmbeddingGemma series. Thanks for following along!
embeddinggemma - View on GitHub
This post is part of my daily AI journey blog at Mosaic Mesh AI. Building in public, learning in public, sharing the messy middle of AI development.