
Building an Agentic Personal Trainer - Part 7: LLM Provider Abstraction
This is Part 7 of a series on building an agentic personal trainer. Read Part 1 for architecture, Part 2 for tools, Part 3 for the system prompt, Part 4 for Garmin integration, Part 5 for duplicate detection, and Part 6 for memory.
Running AI locally has no API costs—just electricity. Cloud providers charge per token. I wanted to switch between local and cloud models without rewriting my agent code.
A simple factory pattern handles provider switching (llm-factory.js):
export function createLLM(provider = null) {
const llmProvider = provider || process.env.LLM_PROVIDER || 'local';
const temperature = parseFloat(process.env.TEMPERATURE || '0.7');
const maxTokens = parseInt(process.env.MAX_TOKENS || '2048');
switch (llmProvider.toLowerCase()) {
case 'local':
return new ChatOpenAI({
openAIApiKey: 'not-needed',
configuration: {
baseURL: process.env.LM_STUDIO_URL || 'http://localhost:1234/v1'
},
modelName: 'local-model',
temperature,
maxTokens,
});
case 'gemini':
return new ChatGoogleGenerativeAI({
modelName: "gemini-2.0-flash",
apiKey: process.env.GOOGLE_API_KEY,
temperature,
maxOutputTokens: maxTokens,
});
case 'claude':
throw new Error('Claude support not installed. Run: npm install @langchain/anthropic');
}
}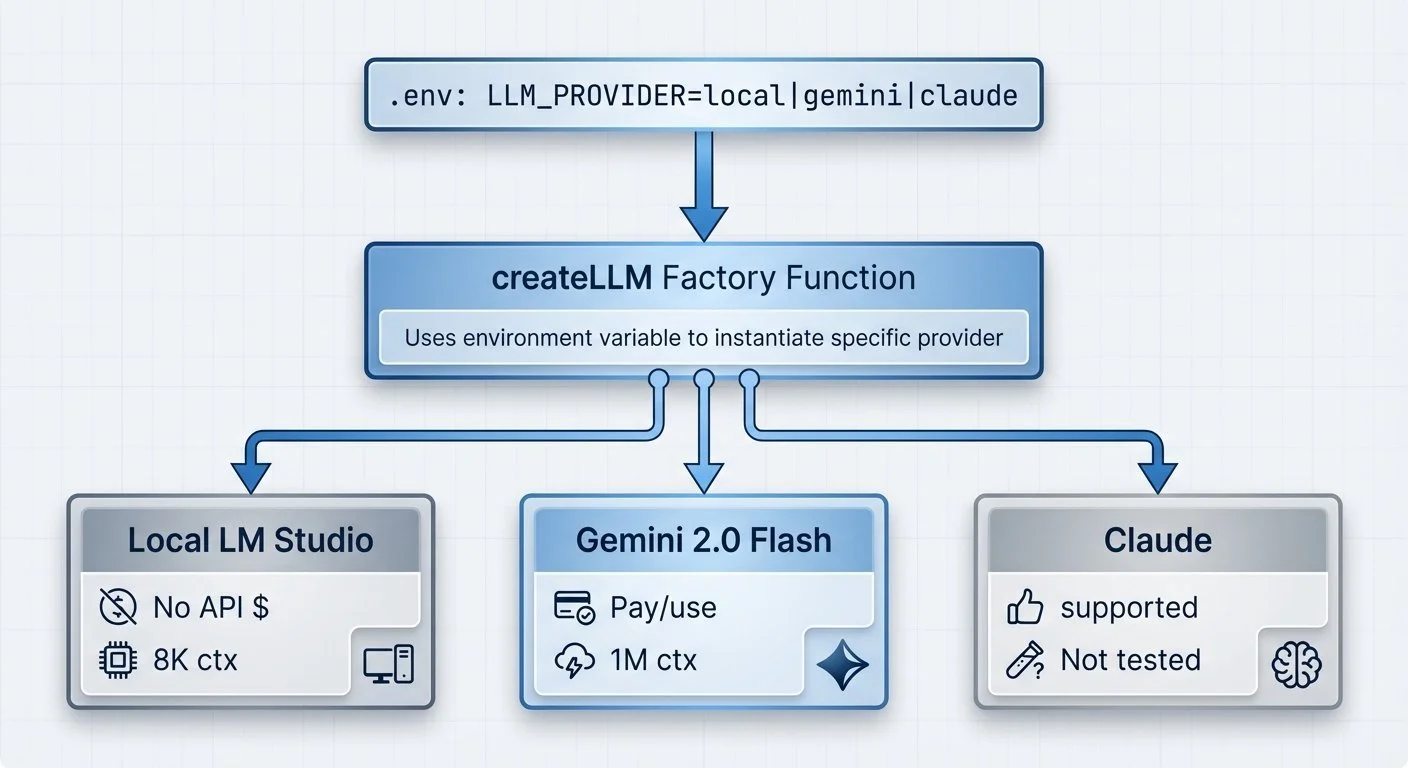
LLM provider abstraction: Factory pattern: one environment variable switches between local, Gemini, and Claude
LM Studio exposes an OpenAI-compatible API, so local models slot right in using LangChain's ChatOpenAI class. Llama 3.1 8B runs well on modern Apple Silicon (M-series chips with sufficient RAM)—good enough for coaching conversations, completely private, with no API costs.
The tradeoffs for this prototype:
- Local (LM Studio): No API costs, ~2-3 second responses, 100% private, ~8K context window
- Gemini 2.0 Flash: Pay per token, ~1 second responses, 1M context window
- Claude: Supported by abstraction, not yet tested in this project
For a personal project I use daily, local wins. For production with users expecting speed, Gemini or CLaude makes sense. The factory pattern lets me flip a switch in .env:
LLM_PROVIDER=gemini
# or
LLM_PROVIDER=localThere's also a helper function (llm-factory.js:50-60) for human-readable provider names in logs:
export function getLLMProviderName(provider = null) {
const llmProvider = provider || process.env.LLM_PROVIDER || 'local';
const names = {
'local': 'LM Studio (Local)',
'gemini': 'Google Gemini',
'claude': 'Anthropic Claude'
};
return names[llmProvider.toLowerCase()] || llmProvider;
}Local-first development changes how you think about AI projects. When inference is free, you experiment more freely. Testing different system prompt variations becomes frictionless—no need to ration API calls or track costs during development.
The abstraction cost is minimal—one 62-line file. The flexibility is worth it. Start with local for development, switch to cloud providers for speed, compare different models and versions—all with a single environment variable change.
Next: testing and debugging agents—the part nobody talks about.
Part 7 of 9 in the Agentic Personal Trainer series.
agentic-personal-trainer - View on GitHub
This post is part of my daily AI journey blog at Mosaic Mesh AI. Building in public, learning in public, sharing the messy middle of AI development.