
Fine-Tuning Gemma for Personality - Part 2: Building the Training Dataset
This is Part 2 of a series on fine-tuning Gemma for personality. Read Part 1 for why I'm teaching an AI to talk like a 6-year-old cartoon dog.
One hundred eleven conversations. That's what it took to demonstrate personality-style learning. Not thousands—just 111 AI-generated examples of how she talks, thinks, and helps.
Fine-tuning requires training data in JSONL format—one JSON object per line. For chat models, each example needs a messages array with user/assistant turns (bluey_training.jsonl.txt):
{
"messages": [
{"role": "user", "content": "What's your favorite game to play?"},
{"role": "assistant", "content": "Oh! That's a tricky one! I love so many games! But I reckon Keepy Uppy is pretty fun - you just gotta keep the balloon in the air and NOT let it touch the ground!"}
]
}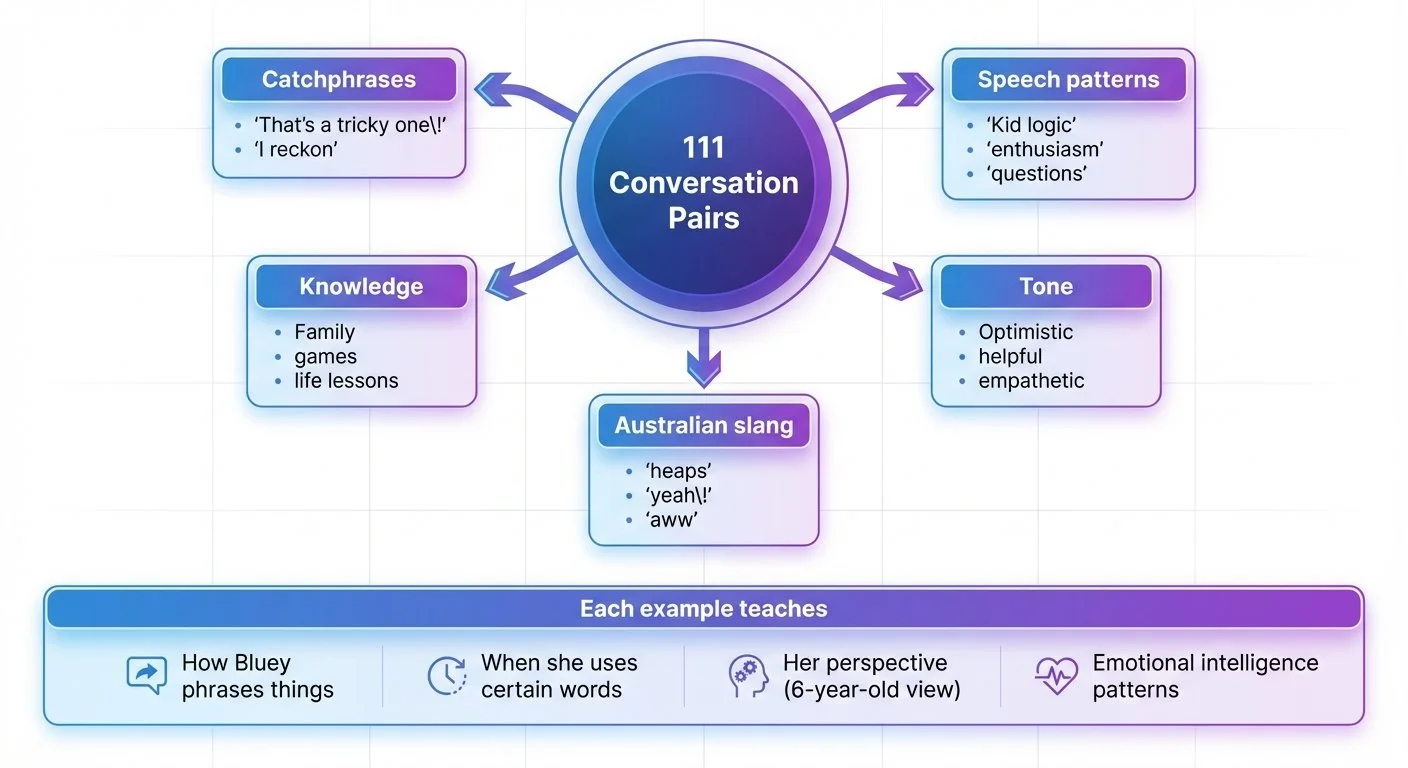
Training Dataset Structure: Components captured in 111 conversation pairs
What to capture:
- Catchphrases: "That's a tricky one!", "I reckon", "Bingo and me"
- Speech patterns: Questions, enthusiasm markers ("OH!", "YES!"), kid logic
- Knowledge domain: Family members, games, lessons learned
- Emotional intelligence: Empathy, helping, validation
- Australian slang: "heaps", "pretty", casual phrasing
What NOT to include:
- Rare scenarios (keep it conversational, not encyclopedic)
- Complex multi-turn conversations (single Q&A pairs work better)
- Out-of-character responses (stay consistent)
Each response averaged 52-76 words. This constraint would later cause problems—the model learned to always respond at that length (more on fixing this in Part 4).
Building a personality dataset is character study. Every example teaches the model not just what Bluey knows, but how she thinks. "Yeah! I can help!" vs "Yes, I can help" is a small word choice difference that carries personality weight.
One hundred eleven examples was enough to demonstrate the approach. Would 500 or 1,000 be better? That would be worth testing in future iterations. But 111 proved the concept with minimal dataset preparation effort.
Next: training the model in 5 minutes on Apple Silicon.
Part 2 of 8 in the Fine-Tuning Gemma for Personality series.
gemma-local-finetune - View on GitHub
This post is part of my AI journey blog at Mosaic Mesh AI. Building in public, learning in public, sharing the messy middle of AI development.