
Building an Agentic Personal Trainer - Part 9: Lessons Learned
This is Part 9 of a series on building an agentic personal trainer. Read Part 1 for architecture, Part 2 for tools, Part 3 for the system prompt, Part 4 for Garmin integration, Part 5 for duplicate detection, Part 6 for memory, Part 7 for LLM provider abstraction, and Part 8 for testing and debugging.
Nine posts later, what actually worked? What would I do differently? Here's my retrospective.
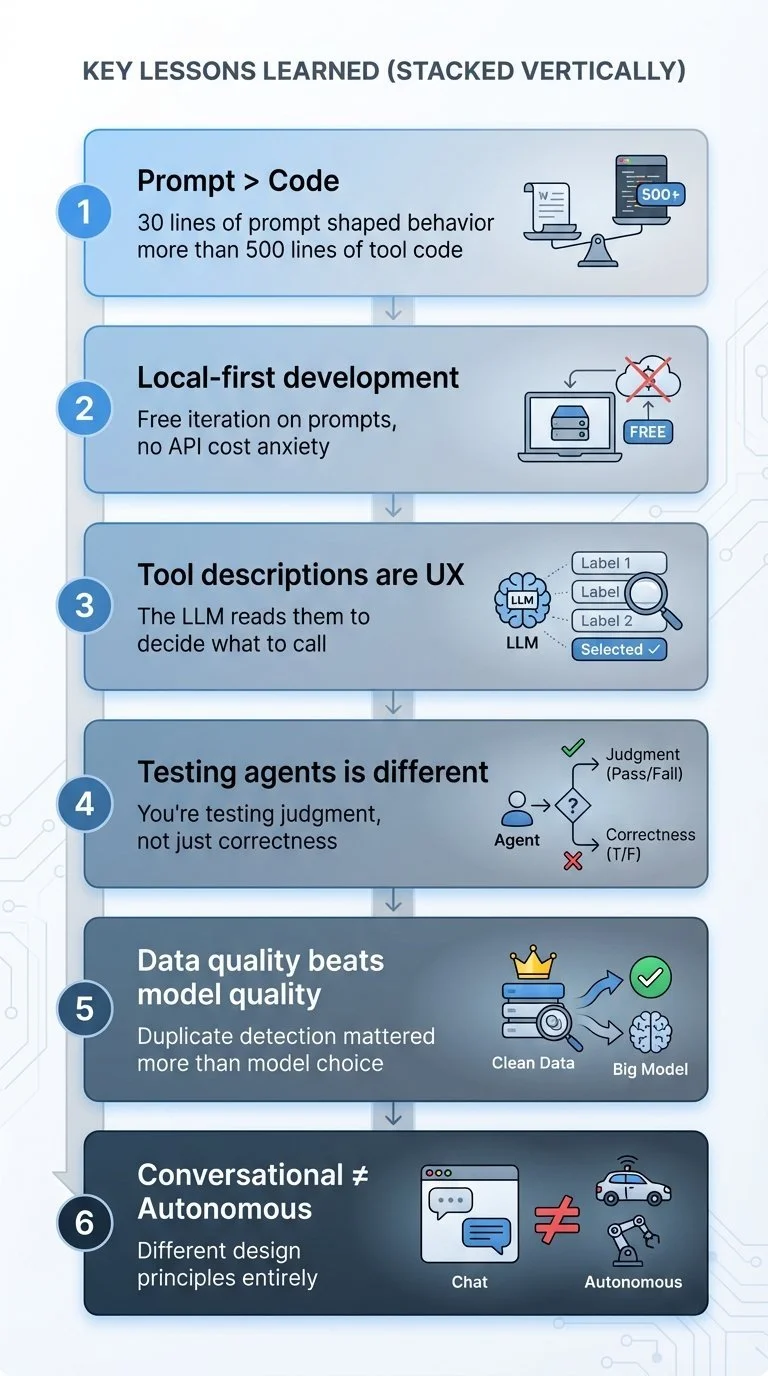
Key lessons learned: Six key lessons from building a conversational AI coach
1. The prompt matters more than the code. The 30-line system prompt shaped behavior more than the 500 lines of tool implementations. "Coach, not drill sergeant" influenced every interaction more than any function. Prompt engineering is character design (see Part 3).
2. Local-first development changes everything. Running Llama 3.1 8B locally meant iterating on prompts without watching API costs. Testing multiple system prompt variations freely led to better results than carefully rationing cloud API calls. The tradeoff: local models have smaller context windows (~8K tokens vs Gemini's 1M), which limits how much conversation history you can load (see Part 6).
3. Tool descriptions are user experience for the LLM. A perfectly coded tool with a vague description never gets called. Getting descriptions right matters as much as the implementation. "Use this to check what injuries the athlete has before recommending workouts" tells the agent when, not just what (see Part 2).
4. Testing agents is fundamentally different. You're not testing for crashes—you're testing for bad judgment. Verbose mode, tool validation, scripted conversations, and tool selection debugging all matter. The agent that confidently gives terrible advice is harder to catch than the one that throws an error. Building test infrastructure uncovered two real bugs that would have been confusing runtime errors (see Part 8).
5. Data quality beats model quality. Garbage in, garbage out applies to AI agents just like any system. When duplicate workouts inflate training loads, even a great model gives bad coaching advice. The duplicate detection system ensures clean data before it reaches the LLM (see Part 5).
6. Conversational agents need different design principles than autonomous ones. My MCP stock trading system optimized for returns. This system optimizes for relationship. The agent asks "how are you feeling?" not because it's polite, but because that information shapes better suggestions. Feelings > metrics isn't soft—it's strategic.
The biggest surprise: how much the "Feelings > Metrics" philosophy improved actual coaching quality. When the agent asks about energy levels before suggesting workouts, it catches things data can't—bad sleep, work stress, lingering fatigue. The human in the loop isn't a limitation; it's the feature.
The prototype accomplished what it set out to do: prove that conversational AI coaching can be built. Future enhancements are clear from the infrastructure already in place: implement the learned preferences system to automatically detect patterns ("you always skip strength on Mondays"), use vector embeddings for relevance-based conversation retrieval instead of just loading the last 5, refine the Garmin sync process and duplicate detection heuristics, explore LLM-based duplicate detection, and improve unit measurement handling for different workout types. But the core is solid—a coaching agent that actually feels like talking to a coach.
Part 9 of 9 in the Agentic Personal Trainer series. Thanks for following along!
agentic-personal-trainer - View on GitHub
This post is part of my daily AI journey blog at Mosaic Mesh AI. Building in public, learning in public, sharing the messy middle of AI development.