
Building an Agentic Personal Trainer - Part 5: Smart Duplicate Detection
This is Part 5 of a series on building an agentic personal trainer. Read Part 1 for architecture, Part 2 for tools, Part 3 for the system prompt, and Part 4 for Garmin integration.
When I do an indoor bike workout, my bike computer records it. So does Wahoo SYSTM. Then both the bike computer and SYSTM sync to Garmin Connect. Now I have two records of the same ride. My agent thinks I'm training twice as much as I am.
The Garmin sync (from Part 4) handles basic sync integrity—don't re-import the same Garmin activity twice. But that doesn't solve the real problem: two different Garmin activities for the same workout.
The deduplication system uses 2 layers in garmin.js:
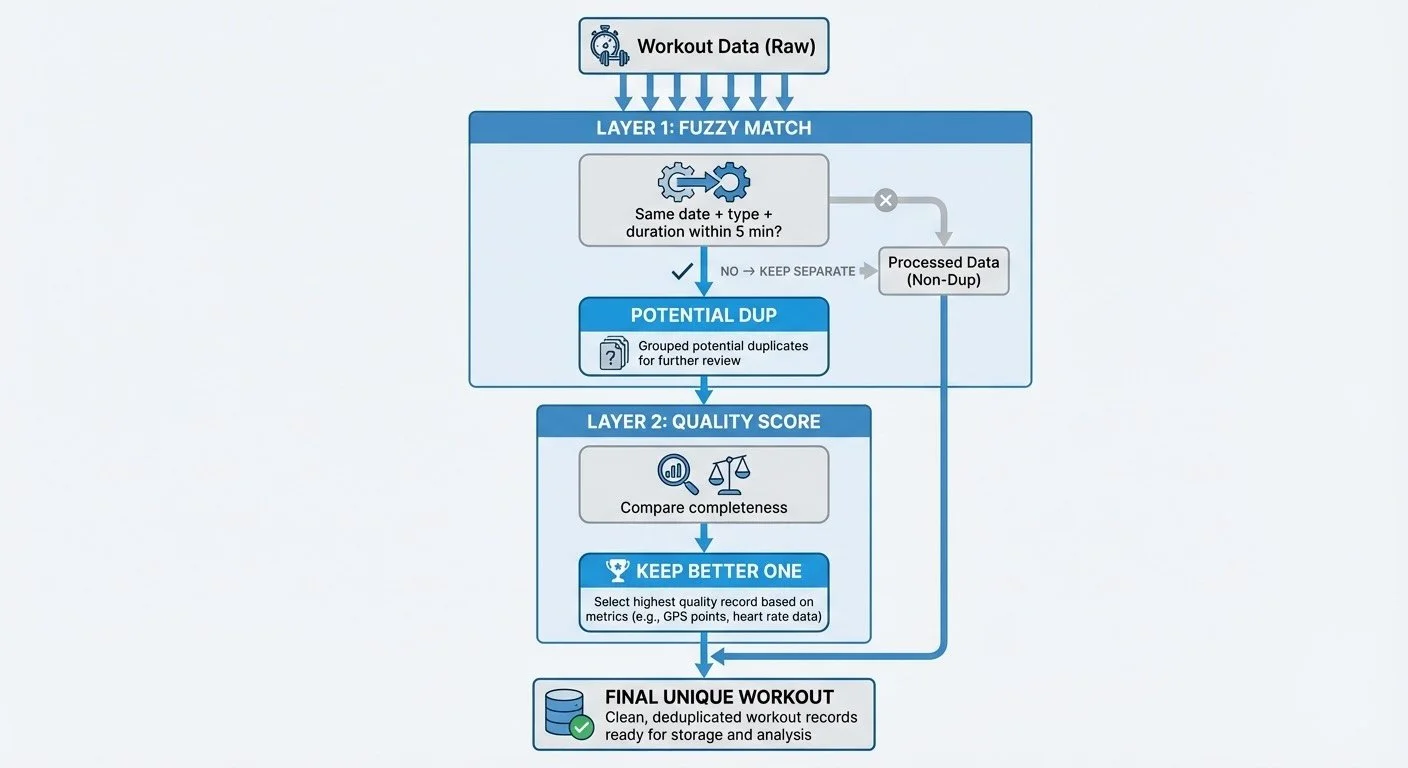
2-layer deduplication: Two layers of duplicate detection: fuzzy matching and quality scoring
Layer 1: Same-day fuzzy matching (garmin.js:64-79). Find workouts with same date, same type, and duration within 5 minutes. This catches the bike computer + SYSTM scenario—different Garmin activity IDs, but clearly the same workout.
function findPotentialDuplicates(date, workoutType, durationMinutes) {
return db.prepare(`
SELECT * FROM completed_workouts
WHERE date = ? AND workout_type = ?
AND ABS(duration_minutes - ?) <= 5
`).all(date, workoutType, durationMinutes);
}Layer 2: Quality scoring (garmin.js:84-102). When duplicates exist, keep the better one. The scoring function prefers data completeness and direct device recordings over third-party syncs:
function scoreWorkout(workout) {
let score = 0;
if (workout.duration_minutes) score += 10;
if (workout.distance) score += 10;
if (workout.notes) score += 5;
// Prefer direct Garmin device over third-party syncs
const notes = workout.notes || '';
if (notes.toLowerCase().includes('wahoo') ||
notes.toLowerCase().includes('systm')) {
score -= 5;
}
if (notes.toLowerCase().includes('avg hr')) score += 3;
if (notes.toLowerCase().includes('cal')) score += 2;
return score;
}When a new workout arrives and potential duplicates exist, the system compares scores. If the new one is better, it deletes the old record and imports the new one. If the existing record is better, it skips the import.
This works for the prototype, but a production system would need further refinement. The hard-coded rules (5-minute tolerance, specific scoring weights) handle common cases but could miss edge cases. Could an LLM identify duplicates more intelligently? Instead of rigid rules, the system could ask: "Here are two workouts—are these the same session?" Worth exploring.
Deduplication is one of those invisible features. When it works, you just don't see duplicates. But when it's wrong, your training load calculations are garbage.
Quality scoring lets the system make judgment calls without user intervention. A 60-minute bike ride with heart rate, power, respiration rate, and cadence data from my bike computer beats a 60-minute bike ride synced from Wahoo SYSTM missing some of this data. The system knows which one to keep.
Next: how the agent remembers conversations and learns preferences over time.
Part 5 of 9 in the Agentic Personal Trainer series.
agentic-personal-trainer - View on GitHub
This post is part of my daily AI journey blog at Mosaic Mesh AI. Building in public, learning in public, sharing the messy middle of AI development.