
Building a Local Semantic Search Engine - Part 5: Learning by Building
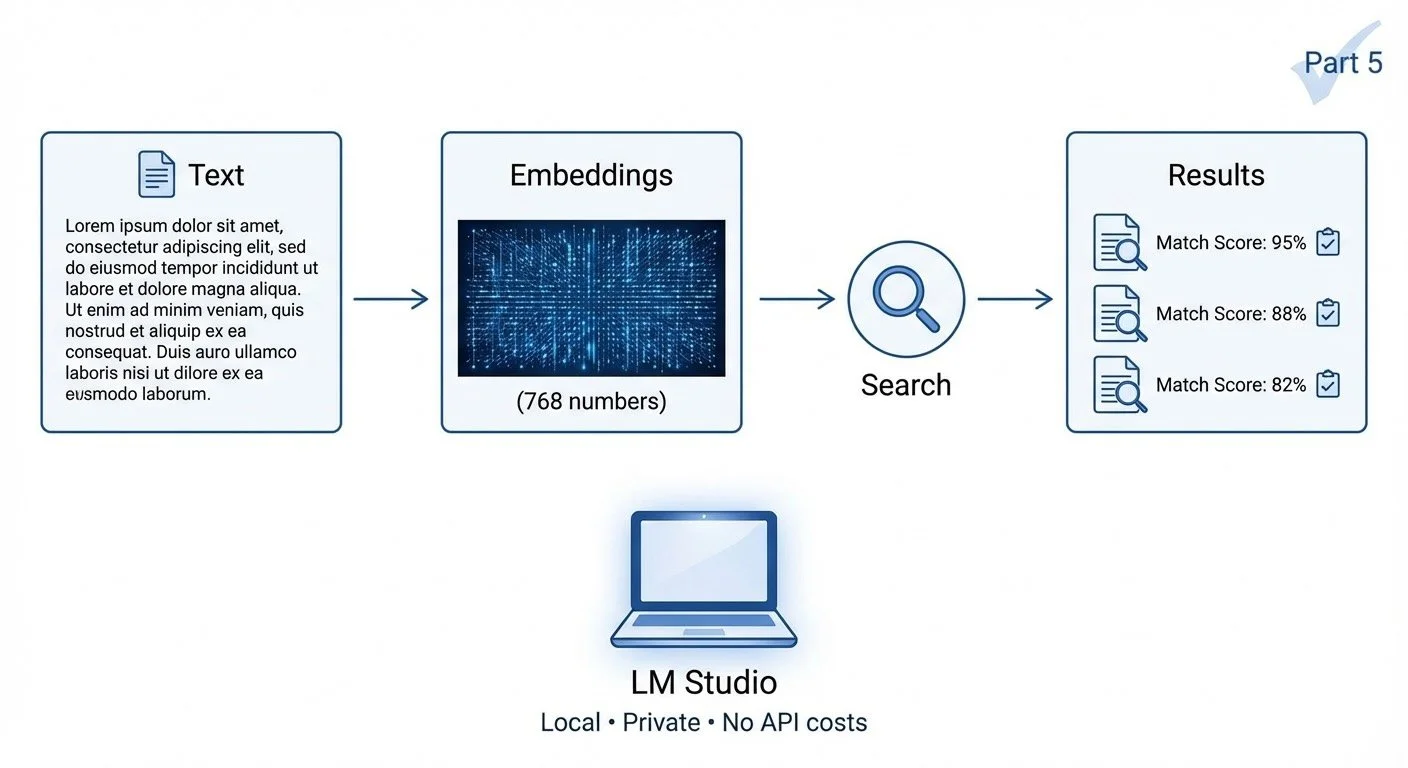
Building a semantic search engine taught me more about embeddings than reading about them ever could. The real value wasn't the tool—it was understanding what those 768 numbers actually mean.

Building a Local Semantic Search Engine - Part 4: Caching for Speed
First search on a new directory: wait for every chunk to embed. A hundred chunks? A few seconds. A thousand? You're waiting—and burning electricity (or API dollars if you're using a cloud service). Second search: instant. The difference? A JSON file storing pre-computed vectors. Caching turned "wait for it" into "already done."
Building a Local Semantic Search Engine - Part 3: Indexing and Chunking
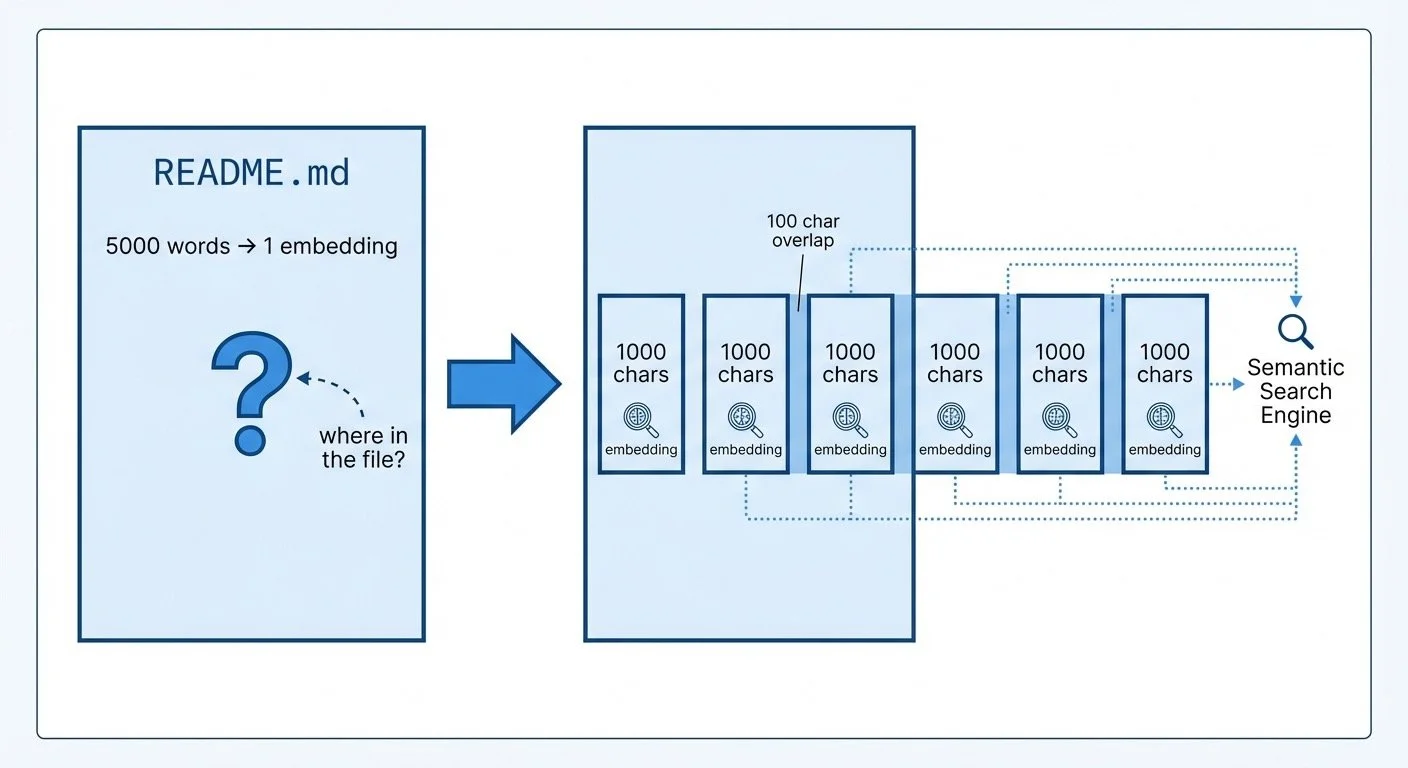
I pointed the search engine at itself—indexing the embeddinggemma project's own 3 files into 20 chunks. Why 20 chunks from 3 files? Because a 5,000-word README as a single embedding buries the relevant section. Chunking solves that.
Building a Local Semantic Search Engine - Part 2: From Keywords to Meaning
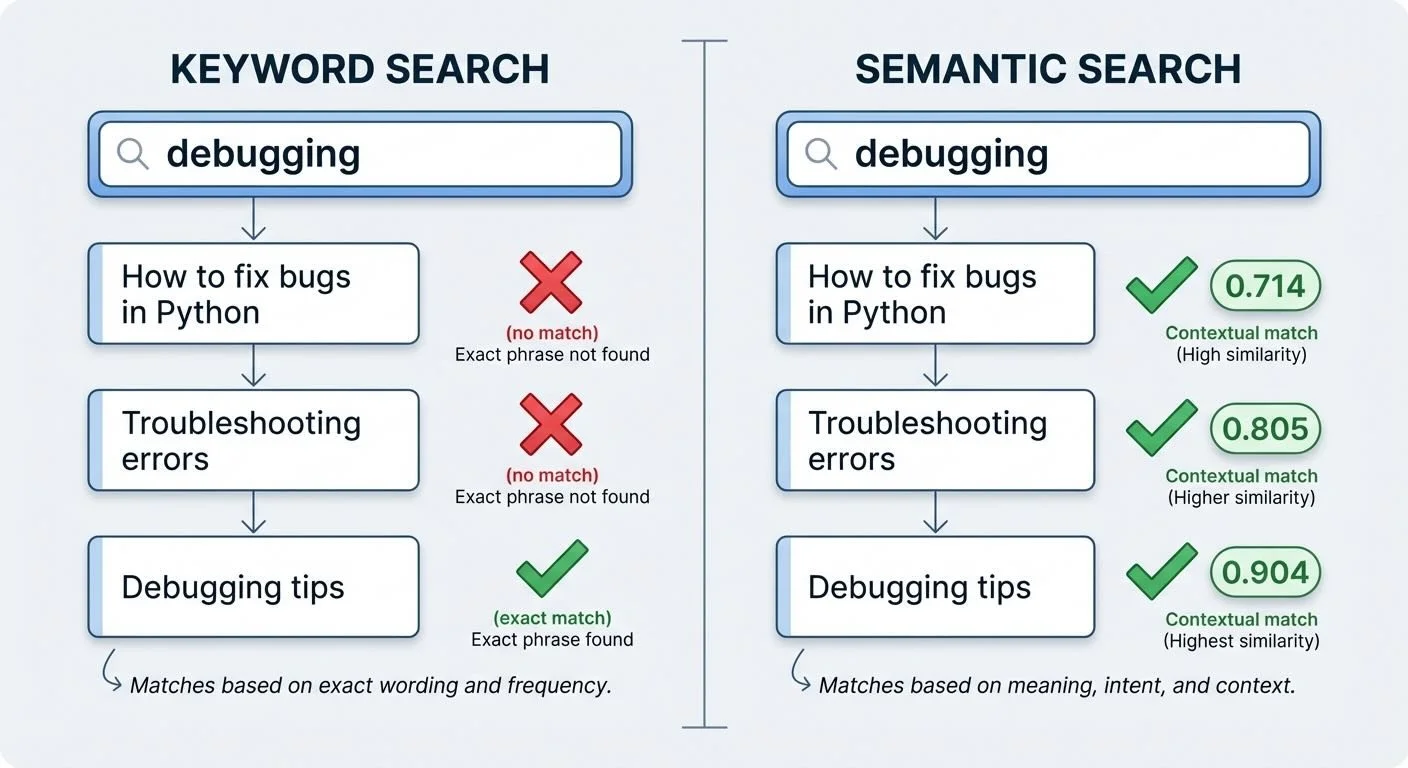
Traditional search fails when you don't remember the exact words. Searching "debugging" won't find your notes about "fixing bugs." Semantic search finds them anyway—because it searches by meaning, not keywords.
Building a Local Semantic Search Engine - Part 1: What Are Embeddings?
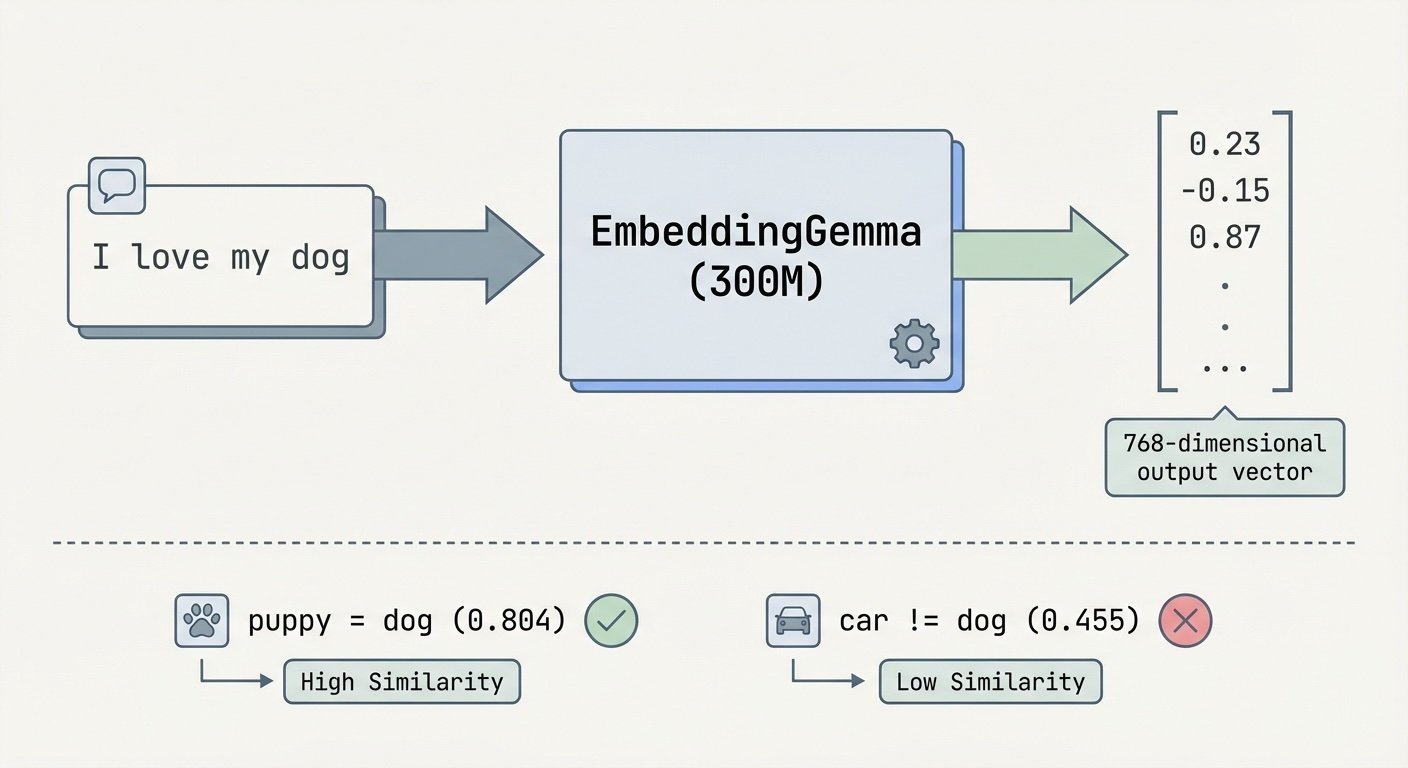
"I love playing with my dog" and "My puppy is so playful and fun" are 80.4% similar. Compare that to "Cars are expensive to maintain"—only 45.5% similar. How does a computer know that? Embeddings—and I wanted to run them entirely on my laptop.