
The Bart Test - Part 4: When My Teen Judges Ghosted Me
This is Part 4 of the Bart Test series. Read Part 1, Part 2, and Part 3 for the OLMo experiments and initial teen feedback.
I tested GPT-5.2, Claude Opus 4.5, and Gemini 3 Pro with the baseline prompt. The outputs were ready. I sent the first story (GPT's 1,540-word epic) to my kids via text.
No response.
I waited a few days. Still nothing.
A week passed. They weren't being difficult. They just... didn't respond.
Here's what I had asked them to do:
"Hey, can you read this 1,540-word AI-generated story about a developer deploying code to production on a Friday afternoon, rate it on four different 1-10 scales, and give me qualitative feedback on what feels forced or authentic?"
When I write it out like that, the problem becomes obvious.
This is hard work. And not just hard—it's specialized work that requires:
- Technical context they don't have (what's a deployment pipeline?)
- Cultural expertise in a narrow domain (Gen-Alpha slang)
- Time and focus (reading 500-1500 words per story, times 3 stories)
- Repeated commitment (every time I test a new model)
These kids had been incredibly generous with their time. They gave me detailed feedback on five previous outputs. They taught me about "trying too hard" and dated slang. They gave me the "zoo not duck" metaphor that perfectly captured the problem.
But somewhere along the way, I stopped asking for a favor and started asking for unpaid labor.
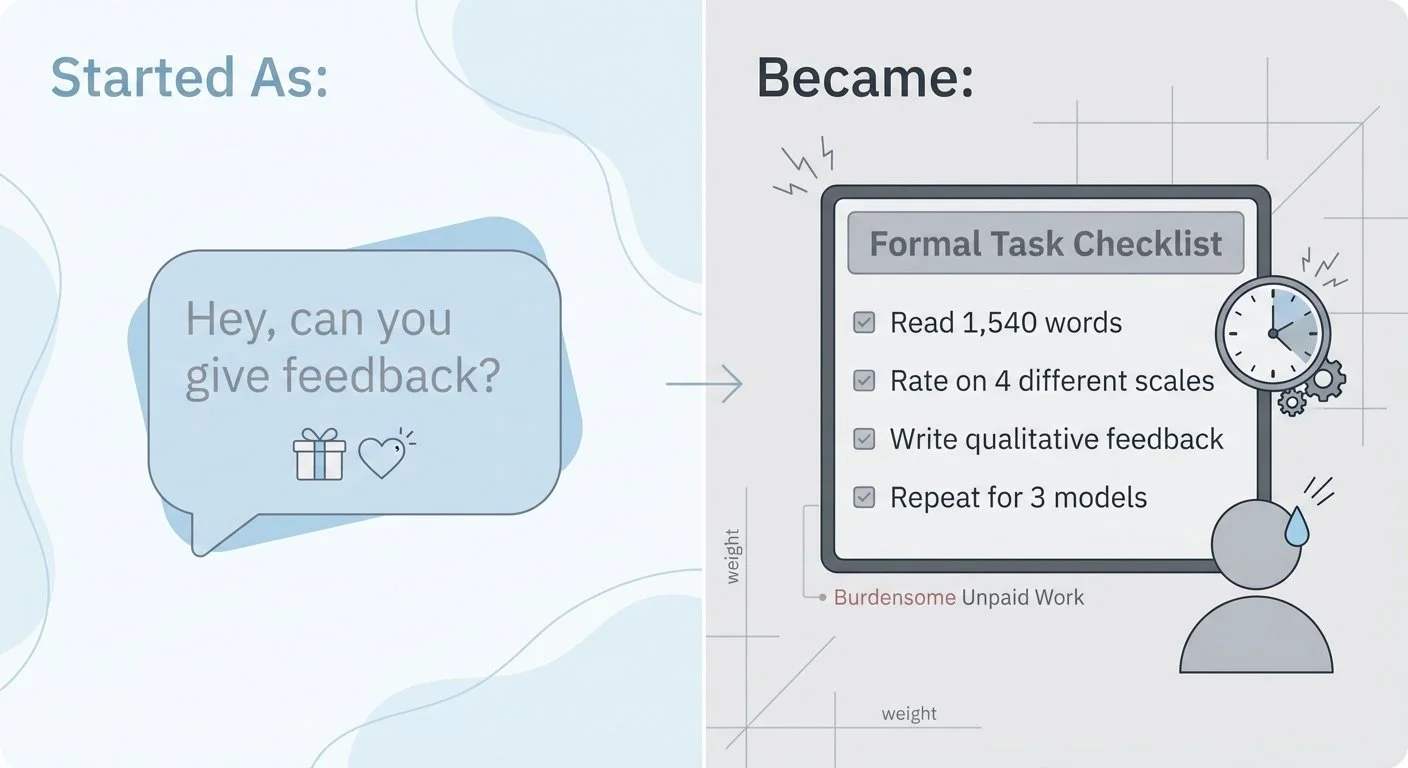
The shift from casual favor to structured work: what started as friendly feedback became a demanding evaluation task
Even if I could solve the motivation issue (pay more, make it fun, whatever), there's a deeper structural problem: Per-model validation doesn't scale.
The Bart Test seemed interesting—measuring AI cultural fluency through teen judges. But to be sustainable, I'd need:
- Teens to evaluate every new model's output as it releases
- Consistent judging over months
- Fast turnaround times
- Reasonable compensation
That's not a benchmark. That's a part-time job for these judges.
The realization: A benchmark that's too difficult for humans to judge probably isn't a sustainable benchmark.
Compare to Simon Willison's pelican-on-a-bike test:
- Anyone can judge it in 2 seconds
- No specialized knowledge required
- Doesn't expire or require updates
- Works until models solve it
The Bart Test requires cultural experts (teenagers) to evaluate cultural fluency (Gen-Alpha slang). That's inherently hard. Fighting that constraint wasn't working.
I had to rethink everything. The hybrid evaluation worked—but only if I could keep judges engaged. Time for a complete methodology redesign.
Part 4 of 9 in the Bart Test series.
bart-test - View on GitHub
Code References
- GPT-5.2 Output - 1,540 tokens
- Claude Opus 4.5 Output - 373 tokens
- Gemini 3 Pro Output - 496 tokens
This post is part of my AI journey blog at Mosaic Mesh AI. Building in public, learning in public, sharing the messy middle of AI development.