
The Bart Test - Part 3: The Zoo-Not-Duck Problem

The zoo-not-duck problem: AI outputs create overwhelming noise when clear focus is needed
When I asked what made the AI output feel unnatural, Teen #1 said:
"Just didn't seem like very effective communication. It's like if you are trying to paint a picture of a duck and you paint a picture of a zoo with a tiny duck exhibit in the corner. > Too much noise.> "
This metaphor captured the core problem.
I ran Experiment 03 using Claude Sonnet 4.5 to evaluate all five outputs from Experiment 01 and Experiment 02—the baseline from Experiment 01, plus the four variations from Experiment 02. The top two candidates as evaluated by Claude Sonnet 4.5 were then sent to my teenage judges for validation.
The Experiment 03 AI judge results (full analysis):
- Lower Temp (0.5): 5.25/10 ⭐
- Higher Temp (1.0): 5.00/10
- Baseline / Constraints / Style Anchor: 4.50/10 (tied)
The Experiment 03 human judge results (3 teens via text—I recruited a third judge for this round, archived reviews):
- Winner: Lower Temp (0.5) - 2 out of 3 votes
- Second: Baseline (0.7) - 1 vote
Lower temperature won—not because it was great (overall score of 5.25/10 is mediocre), but because it was the least bad. All stories had the same core problem: "trying too hard with slang."
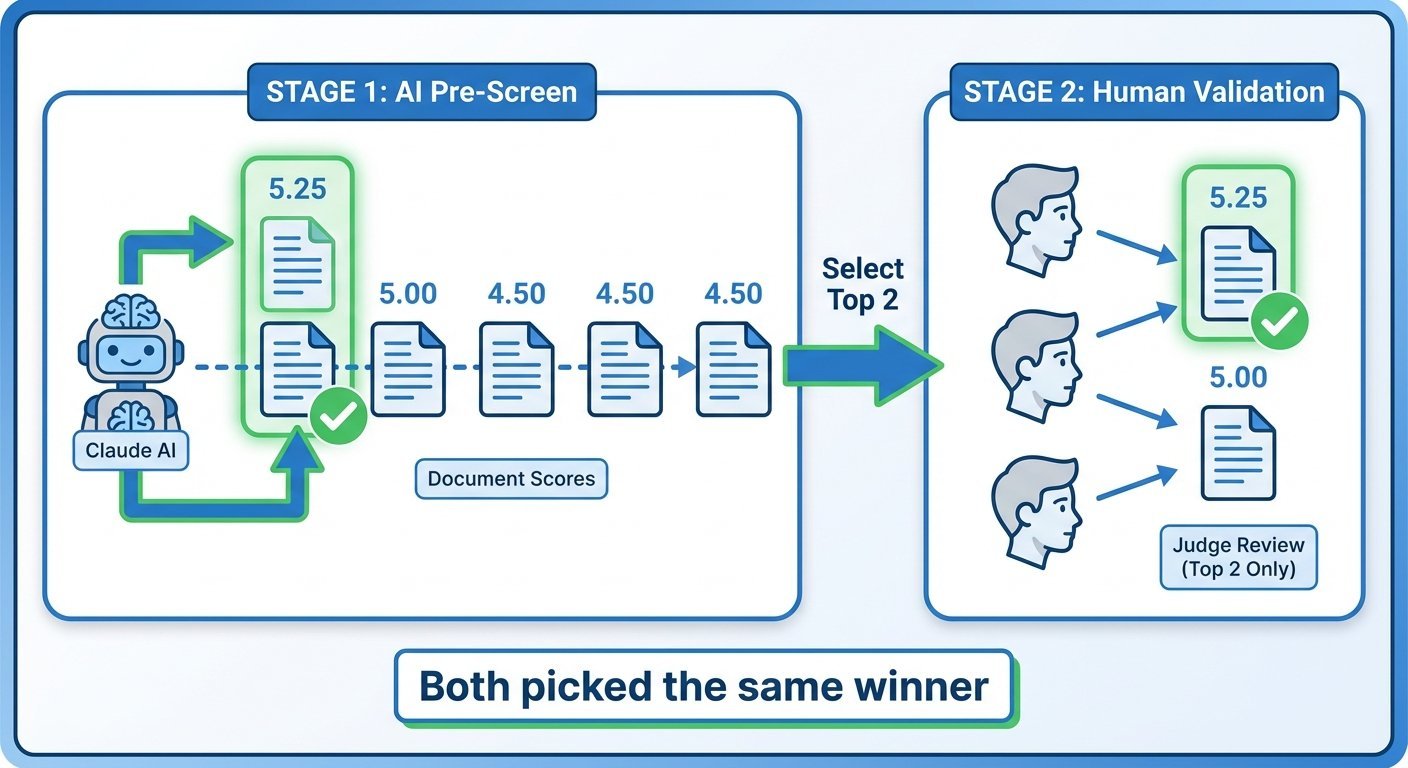
Experiment 03's two-stage hybrid workflow: AI judges pre-screen, humans validate the top candidates
What the teens taught me:
1. The "Too Much Noise" Problem The AI isn't failing at slang—it's failing at focus. It's treating the prompt like a checklist:
- ✅ Gen-Alpha slang? Used 47 terms
- ✅ Emojis? Added 93 of them
- ✅ Friday deploy story? It's in there somewhere
Result: A zoo when you wanted a duck.
2. Slang Has a Half-Life Teen #3 called out specific terms as dated:
- ❌ "no cap" - already feels old
- ⚠️ "vibe" - "isn't used but still sometimes just not as much"
This was December 2025. These terms peaked maybe 6-12 months ago. Language moves FAST at the Gen-Alpha layer.
3. Emoji Currency Matters Teen #3 gave unprompted feedback on emojis:
- ✅ Core set: 😂😭🔥🥀
- ❌ Overusing uncommon emojis - The AI pulled from the full Unicode set
Then added: "The dead rose [🥀] has gotten more popular." I had no idea.
4. Blending > Density Teen #3: "Just the way you say it, still keep some like English in there if you know what I mean. Not everything has to be slang but keep it in there too. Because then it seems like you're trying too hard."
Real people blend registers (levels of formality) fluidly—slang here, normal English there, switching as context demands. The AI seems to treat every sentence as an opportunity to insert slang, rather than blending naturally.
Experiment 03's hybrid AI/human evaluation approach showed signs of alignment. AI judges and human judges picked the same winner, showing that:
- ✅ AI judges can pre-screen quickly
- ✅ Humans provide the ground truth
- ✅ Together, they can scale better than human judges alone
But the key finding: "Trying too hard" is a consistent, identifiable pattern. All three teens independently spotted it. This isn't subjective vibes—it's a reproducible signal about slang density, register (formality level) switching, and optimization for "doing the task" vs. "sounding natural."
Traditional benchmarks focused on accuracy or task completion wouldn't catch this. You need actual teenagers to catch it.
These insights were fascinating. So I decided next to test frontier models—GPT, Claude, Gemini (rather than smaller open-weight models like OLMo3)—to see if they could avoid the "trying too hard" problem. I needed to know if this was a real challenge or a solved problem. Then my teens stopped responding. Tune in for parts 4-6 to find out what happens next.
Part 3 of 9 in the Bart Test series.
bart-test - View on GitHub
Code References
- AI Judges Script - Claude evaluation code
- Human Reviews - Teen feedback data
This post is part of my AI journey blog at Mosaic Mesh AI. Building in public, learning in public, sharing the messy middle of AI development.