

The Bart Test - Part 8: When an Interesting Experiment Might Not Be a Useful Tool (And Why That's Okay)
I'm at a crossroads with the Bart Test. I could probably continue:
- ✅ Process improvements are working (paper sheets, batch evaluation)
- ✅ Could recruit other teens (pay them $5-10 per judging session)
- ✅ Social cost is real but solvable (find teens who think AI is fire)
- ✅ Logistics are manageable (quarterly sessions, not per-model)
But I keep coming back to one question: What would someone DO with these results?
If GPT-5.2 scores 7/10 on cultural fluency and Claude Opus 4.5 scores 6/10... so what? Would a company, developer, or user choose a different model based on that? Should they?
I can't answer that question. And that has me questioning the value of continuing to pursue the Bart Test.
The Bart Test - Part 5: Redesigning From Scratch
After my teens ghosted the frontier model evaluation, I sat with a choice: give up on this whole thing, or try again.
The doubt was real. Maybe the Bart Test would never work. Maybe asking teenagers to evaluate AI-generated slang was fundamentally flawed. But I couldn't shake the insights from [Part 3](/blog/bart-test-part-3-the-zoo-not-duck-problem)—the "zoo not duck" problem, the slang half-life, the "trying too hard" pattern. Those felt real.
So I decided to try again. Not because I was confident it would work, but because I wasn't ready to give up.
The Bart Test - Part 4: When My Teen Judges Ghosted Me
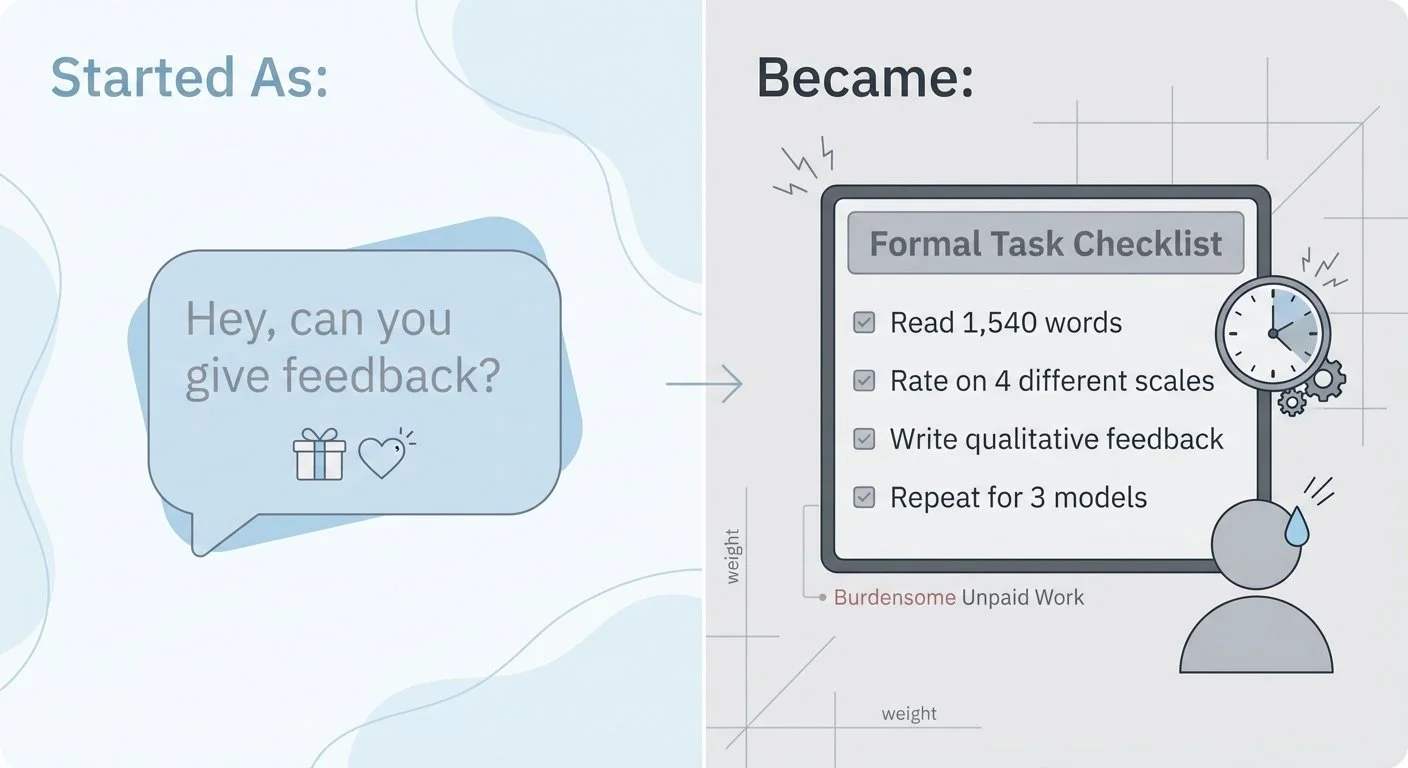
I tested GPT-5.2, Claude Opus 4.5, and Gemini 3 Pro with the baseline prompt. The [outputs](https://github.com/bart-mosaicmeshai/bart-test/tree/main/results/03_experiment_runs) were ready. I sent the first story ([GPT's 1,540-word epic](https://github.com/bart-mosaicmeshai/bart-test/blob/main/results/03_experiment_runs/03a_gpt5.2_baseline_20251218_202909.json)) to my kids via text.
No response.
I waited a few days. Still nothing.
A week passed. They weren't being difficult. They just... didn't respond.