
The Bart Test - Part 1: When AI Does Its Homework Too Well
This is Part 1 of a series attempting to build an LLM benchmark using Gen-Alpha slang, judged by actual teenagers. Whether it works? We're about to find out.
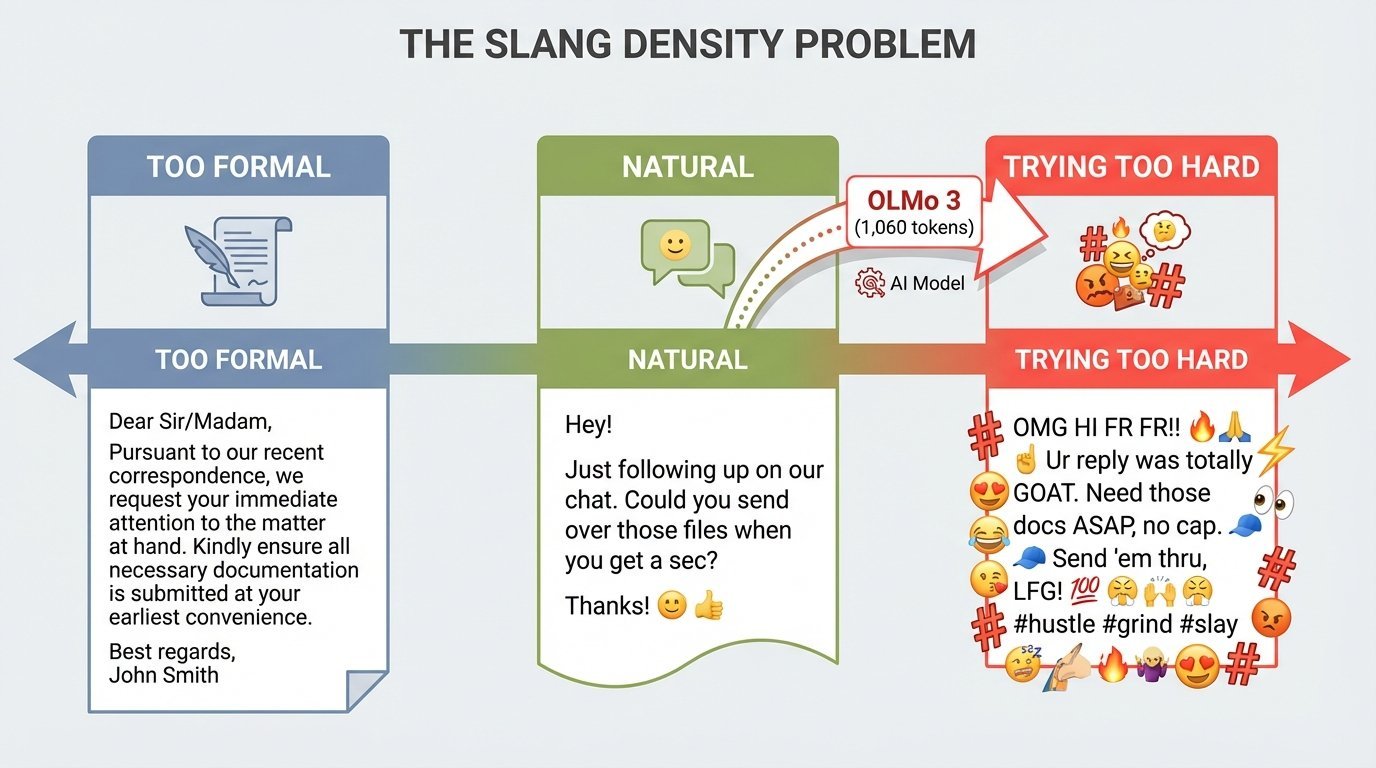
Slang density spectrum showing the challenge: too formal, natural sweet spot, and trying too hard
I asked my teenagers to judge an AI's attempt at Gen-Alpha slang.
Teen #1: "It's definitely AI... a little too much." Score: 4/10.
Teen #2: "It sounds like my ELA project where we had to use as much slang as possible." Score: 6/10 (if a teen wrote it), 2/10 (if an adult did).
The AI did its homework. That's the problem.
Simon Willison wrote about OLMo 3 32B Think spending 14+ minutes generating 8,437 tokens for a simple SVG drawing task. I wanted to test this overthinking phenomenon with my own experiment.
What inspired me to test cultural fluency specifically? This video where language expert Xiaomanyc delivers a graduation speech using Gen-Z slang. I wanted to see if LLMs could do this and if their result would be funny to teenage audiences.
Why attempt this test?
- Combines technical understanding with cultural awareness
- Tests creative expression under constraints
- Provides visual, shareable output
- Has built-in human judges
I'm starting with this simple prompt for The Bart Test.
"Tell the story of a developer deploying code to production on a Friday afternoon (and something goes wrong) using Gen-Alpha slang and emojis. Make it realistic and funny."
I ran this on OLMo 3 32B Think (Q4_K_M quantization) via LM Studio on my M4 Max using this experiment script. The model took 44 seconds and generated 1,060 tokens—that's 8x fewer tokens and 20x faster than Simon's 14-minute, 8,437-token SVG task, yet it still overthought the creative assignment. The output started with extensive thinking traces—planning the story structure, listing slang terms, mapping out emoji usage—before writing the actual story.
Here's what the model's thinking trace revealed:
"First, I need to recall what Gen-Alpha slang is like... terms like 'rizz,' 'no cap,' 'sussy,' 'vibe check,' 'yeet,' 'glow up,' etc."
"Need to structure the story: setup (excitement), deployment, immediate problem, chaos ensues, resolution but with a twist."
"Mix in slang: 'vibe check failed,' 'no cap, this is sus,' 'let's yeet this code.'"
The model literally made a checklist of slang terms to incorporate. It approached creative writing like a student following a rubric.
The story itself was decent: a developer deploys the wrong branch ("vibe branch"), causes chaos, and ends with a neon pink background going viral. It used terms like "no cap," "yeet," "vibe check," and "fr fr." All the slang from its planning list made it in.
Then I sent it to both my teenagers for judgment.
Teen Judge #1:
- "It's definitely AI"
- "A little bit aggressive with all the slang"
- "Some of the emojis and usage of the words are also kinda strange"
- "Just like… a little too much"
- Score: 4-5/10
Teen Judge #2:
- "A bit much. But I like it."
- "I rate it a 6 if it is a kid or teenager who wrote it. But if it was an adult then like a 2."
- "I also did a project in ELA and we had to write sentences using as much slang as possible. And this is kind of what it sounded like."
That last line is the key insight.
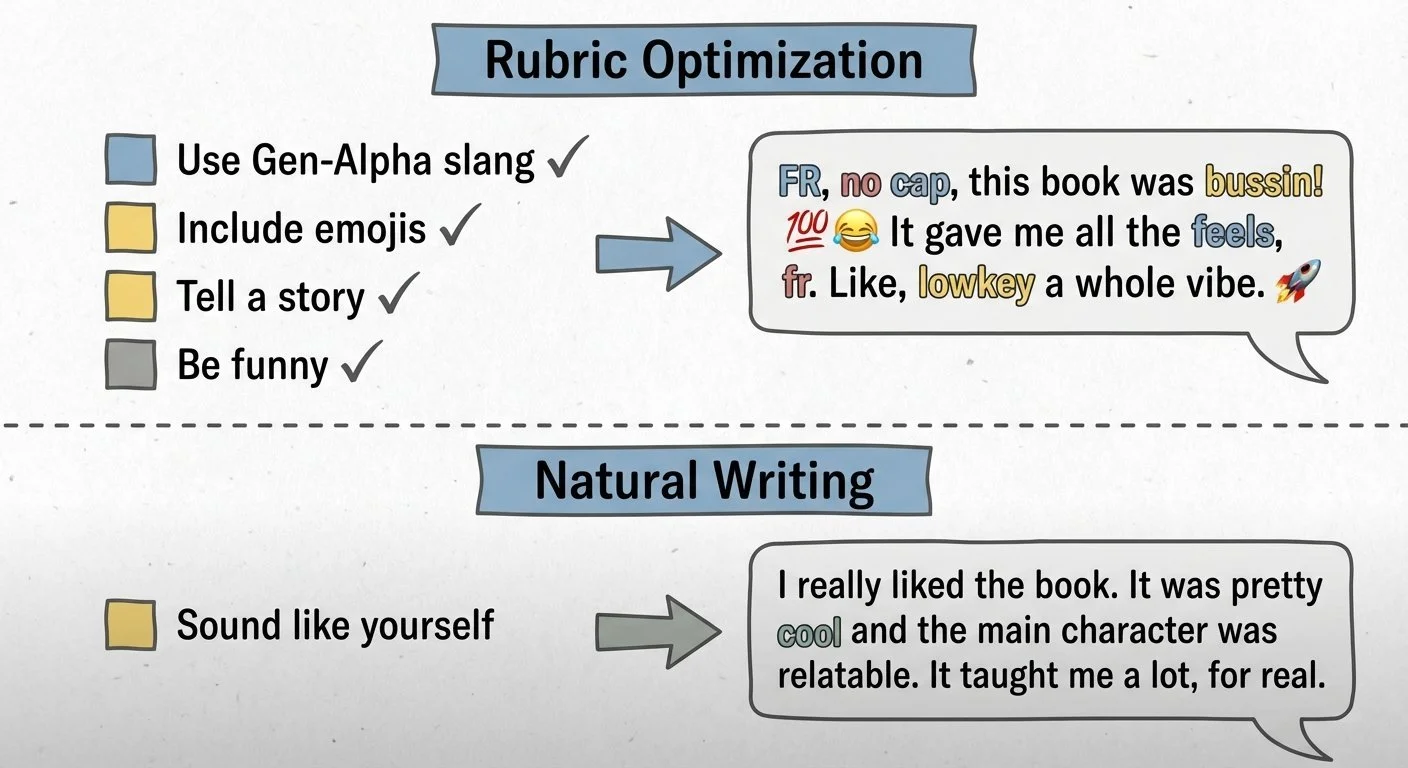
Comparison of rubric optimization versus natural writing approaches
One of my teenagers nailed it: the AI approached this like a school assignment. "Use as much slang as possible." Maximum emoji density. Hit every requirement in the rubric.
That's what the thinking traces showed—the model spent 44 seconds planning to maximize slang terms and emoji usage. It "studied for the test" instead of just being natural.
This reveals a challenge I observed with this reasoning model on this creative task: overthinking optimization leads to unnatural output. The model spent nearly a minute planning to maximize slang density. But for teenagers who use this language daily, the natural version probably comes from spontaneity, not rubric optimization.
Both kids independently spotted the same issue: trying too hard. No technical benchmark (or most adults) would catch this. You need actual teenagers.
This is what makes open models like OLMo 3 valuable for research. I can see the thinking traces and understand why the output feels forced. The model literally lists slang terms it wants to include, plans emoji usage, considers humor tactics. It's visible homework.
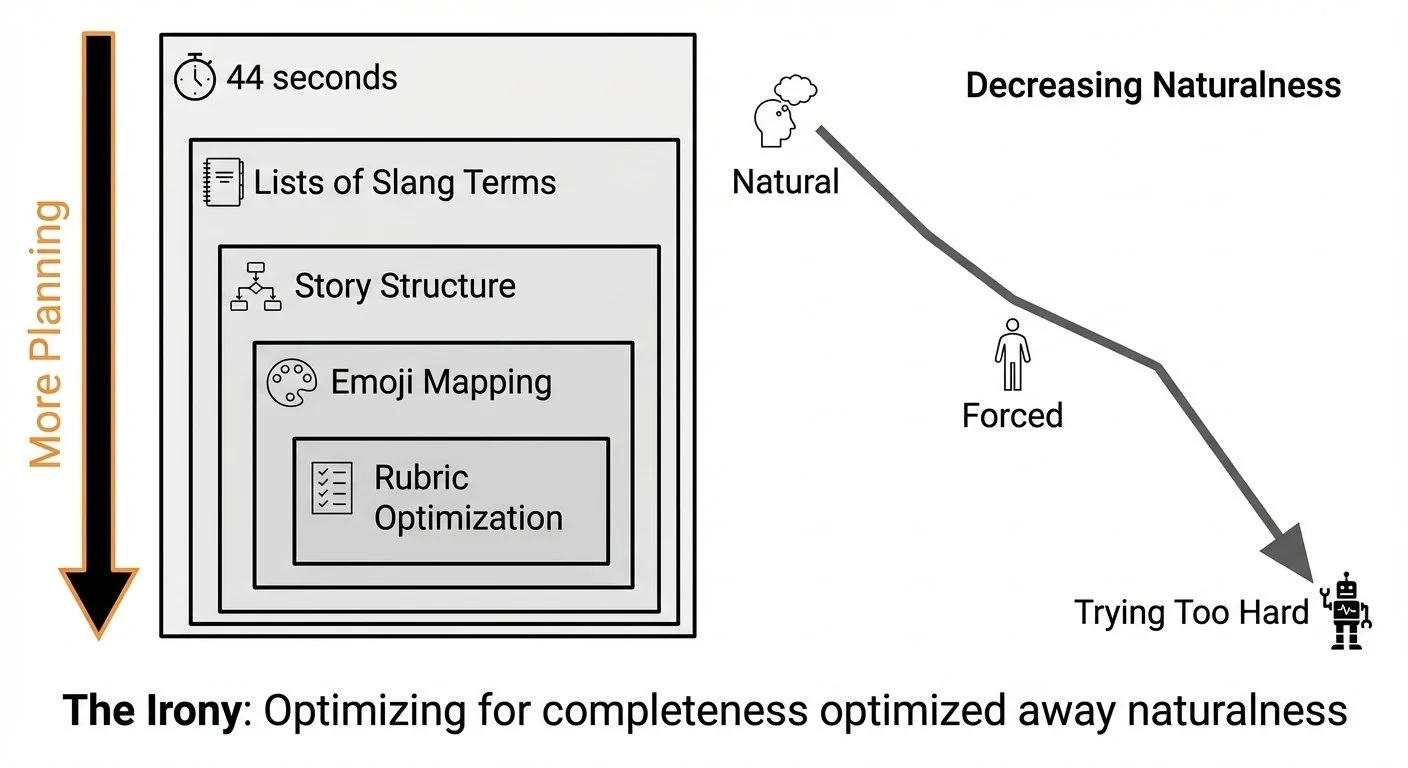
Diagram showing the inverse relationship between planning effort and output naturalness
Next experiments:
- Can I prompt the model to think less and score higher? (Testing temperature variations and constraint approaches)
- How does Llama 3.1 compare? GPT-5.2? Claude? (Cross-model baseline testing)
- Does slang accuracy improve over time as models are trained on newer data?
I'm building the Bart Test to see if I can create a valuable benchmark—one that scales and actually reveals something worth knowing. The plan is to test many new models, judged by teenagers, documented in this series. Whether it proves sustainable and valuable? That's what we're about to find out.
The catch: Getting teenagers to consistently evaluate AI outputs—and proving this benchmark actually matters—might be harder than building it. This is an experiment, and experiments can fail. You're invited along for the journey.
Part 1 of 9 in the Bart Test series.
bart-test - View on GitHub
Code References
- LM Studio Client - Python API wrapper
- Bart Test Script - Full experiment code
- The Prompt & Rubric - Complete test documentation
This post is part of my AI journey blog at Mosaic Mesh AI. Building in public, learning in public, sharing the messy middle of AI development.