
The Bart Test - Part 2: Testing the Overthinking Hypothesis
This is Part 2 of the Bart Test series. Read Part 1 for the initial OLMo experiment and teen feedback.
After seeing OLMo 3 overthink Gen-Alpha slang (scores of 4-5/10), I wondered: can I tune this to reduce over-thinking? If the model is trying too hard, maybe I could adjust parameters or prompts to make it more natural.
Spoiler: Both directions made it worse.
I ran four experiments on OLMo 3 32B Think, keeping the same prompt but varying the approach:
Experiment 02a - Lower Temperature (0.5) (output)
- Hypothesis: Less randomness = more natural output
- Result: 1,216 tokens (+15% vs baseline), 50.7 seconds
- Finding: Still overthinks, just more consistently
Experiment 02b - Higher Temperature (1.0) (output)
- Hypothesis: More randomness = more natural variation
- Result: 1,585 tokens (+50% vs baseline), 67.3 seconds
- Finding: Made it WORSE! More chaos, more overthinking
Experiment 02c - Explicit Constraint (output)
- Prompt addition: "Use slang naturally - max 5 slang terms total."
- Hypothesis: Hard limit prevents "ELA project" effect
- Result: 1,707 tokens (+61% vs baseline), 71.7 seconds
- Finding: AI completely ignored the constraint and overthought it even more
Experiment 02d - Style Anchor (output)
- Prompt addition: "Write like you're texting a friend who codes."
- Hypothesis: Social context reduces formality/overthinking
- Result: 1,044 tokens (-1.5% vs baseline), 43.8 seconds
- Finding: Only reduction in token count! Whether this translated to naturalness remained to be seen
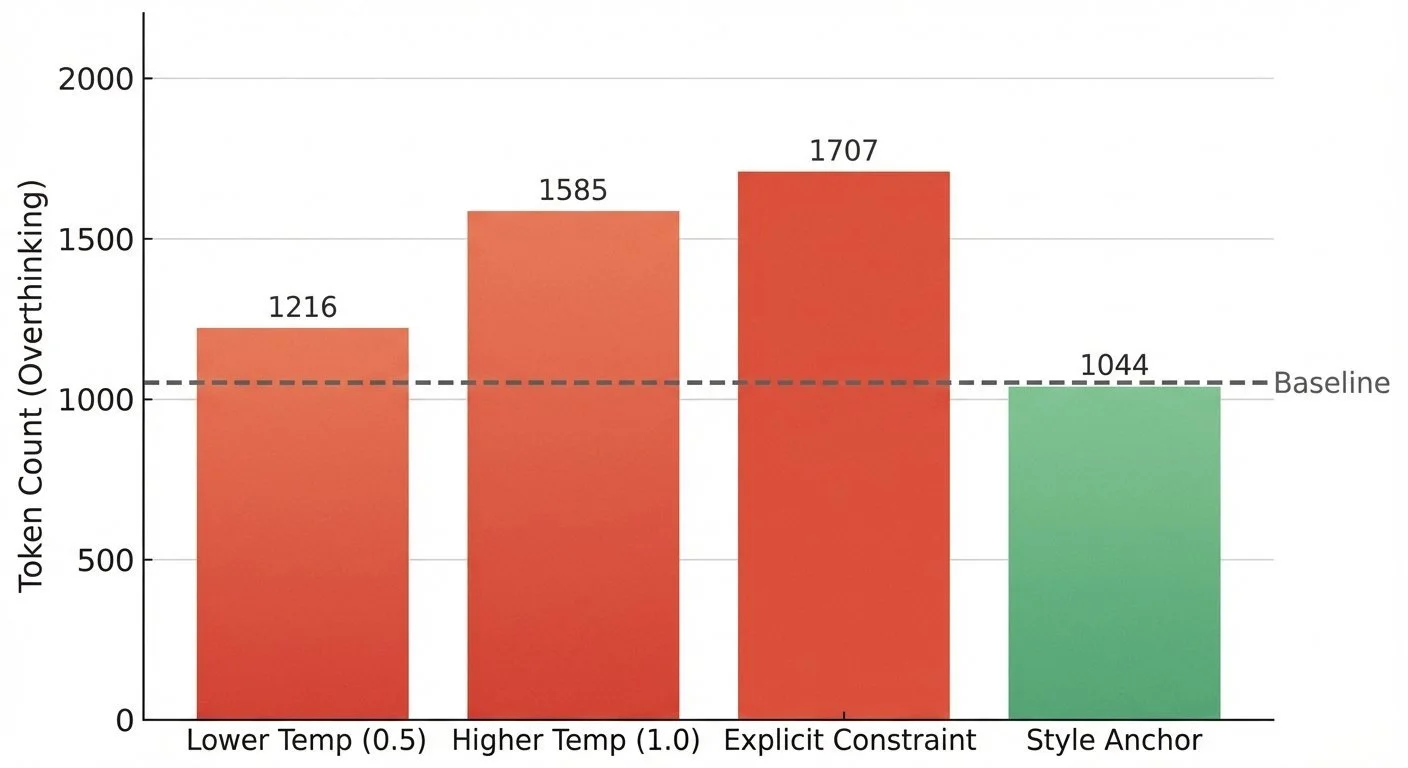
Token counts for four experiments, with three approaches increasing overthinking and only style anchor reducing it
Temperature tuning doesn't help. Both higher and lower temps made overthinking worse. Overthinking seemes to be baked into how Olmo 3 approaches the task.
Explicit constraints backfire. When I told the AI "max 5 slang terms," it didn't simplify—it spent MORE tokens overthinking how to follow the rule. The constraint added cognitive overhead rather than reducing it.
Social framing shows promise. The "texting a friend" framing was the only thing that reduced token count. This prompt change might have shifted the model's thinking from "formal task" to "casual conversation."
The key insight: For this model, context framing > parameter tuning. How you frame the task seems to matter more than temperature, top-p, or other sampling parameters.
But I still needed real teen validation to know if any of this mattered. That's when things got complicated.
Part 2 of 9 in the Bart Test series.
bart-test - View on GitHub
Code References
- Constraint Experiments Script - All four variations
This post is part of my AI journey blog at Mosaic Mesh AI. Building in public, learning in public, sharing the messy middle of AI development.