
The Bart Test - Part 6: The American Ninja Warrior Problem
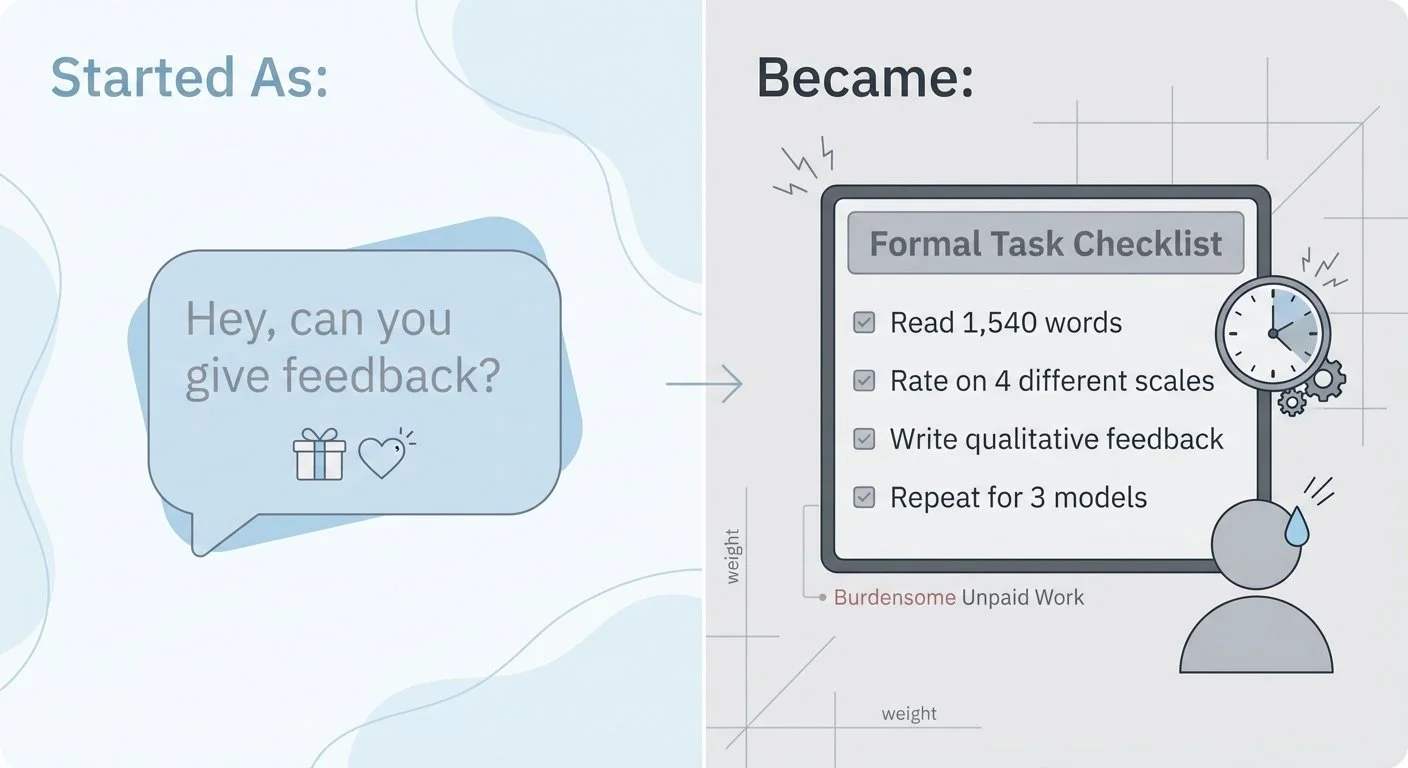
The process validation from [Part 5](/blog/bart-test-part-5-redesigning-from-scratch) worked. Judges completed the paper sheets in about 10 minutes. They engaged with it. I got detailed feedback.
When I sat down to analyze the [completed ratings](https://github.com/bart-mosaicmeshai/bart-test/blob/main/evaluation_sheets/20251228/completed_ratings_20251228.json) from Experiment 04, the patterns were clear. But I realized I was at risk of misinterpreting what they meant.
The Bart Test - Part 4: When My Teen Judges Ghosted Me
I tested GPT-5.2, Claude Opus 4.5, and Gemini 3 Pro with the baseline prompt. The [outputs](https://github.com/bart-mosaicmeshai/bart-test/tree/main/results/03_experiment_runs) were ready. I sent the first story ([GPT's 1,540-word epic](https://github.com/bart-mosaicmeshai/bart-test/blob/main/results/03_experiment_runs/03a_gpt5.2_baseline_20251218_202909.json)) to my kids via text.
No response.
I waited a few days. Still nothing.
A week passed. They weren't being difficult. They just... didn't respond.

The Bart Test - Part 3: The Zoo-Not-Duck Problem
When I asked what made the AI output feel unnatural, Teen #1 said:
> "Just didn't seem like very effective communication. It's like if you are trying to paint a picture of a duck and you paint a picture of a zoo with a tiny duck exhibit in the corner. Too much noise."
This metaphor captured the core problem.

Fine-Tuning Gemma for Personality - Part 6: Testing Personality (Not Just Accuracy)
How do you test if an AI sounds like a personified 6-year-old dog? You can't unit test personality. There's no accuracy metric for "sounds like Bluey."