
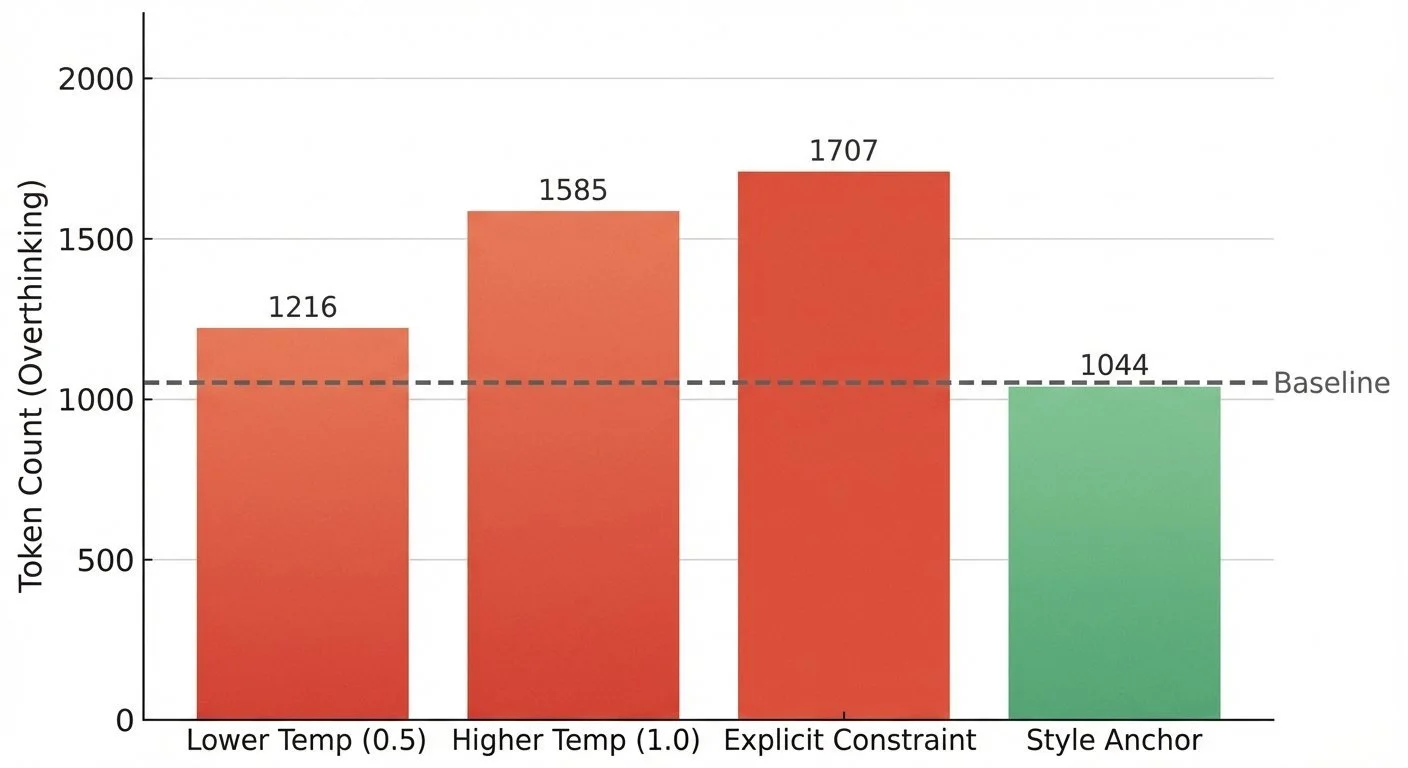
The Bart Test - Part 2: Testing the Overthinking Hypothesis
After seeing OLMo 3 overthink Gen-Alpha slang (scores of 4-5/10), I wondered: can I tune this to reduce over-thinking? If the model is trying too hard, maybe I could adjust parameters or prompts to make it more natural.
Spoiler: Both directions made it worse.
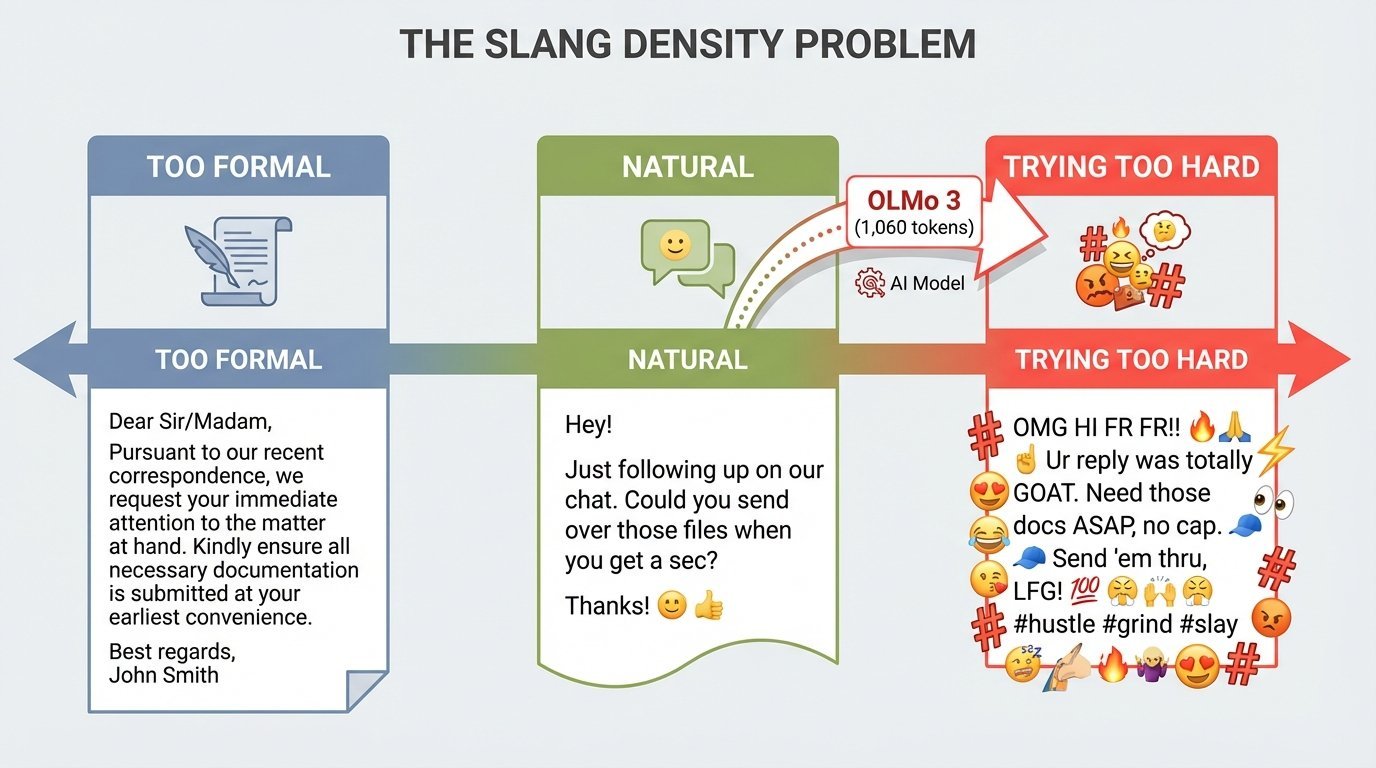
The Bart Test - Part 1: When AI Does Its Homework Too Well
I asked my teenagers to judge an AI's attempt at Gen-Alpha slang.
Teen #1: "It's definitely AI... a little too much." Score: 4/10.
Teen #2: "It sounds like my ELA project where we had to use as much slang as possible." Score: 6/10 (if a teen wrote it), 2/10 (if an adult did).
The AI did its homework. That's the problem.
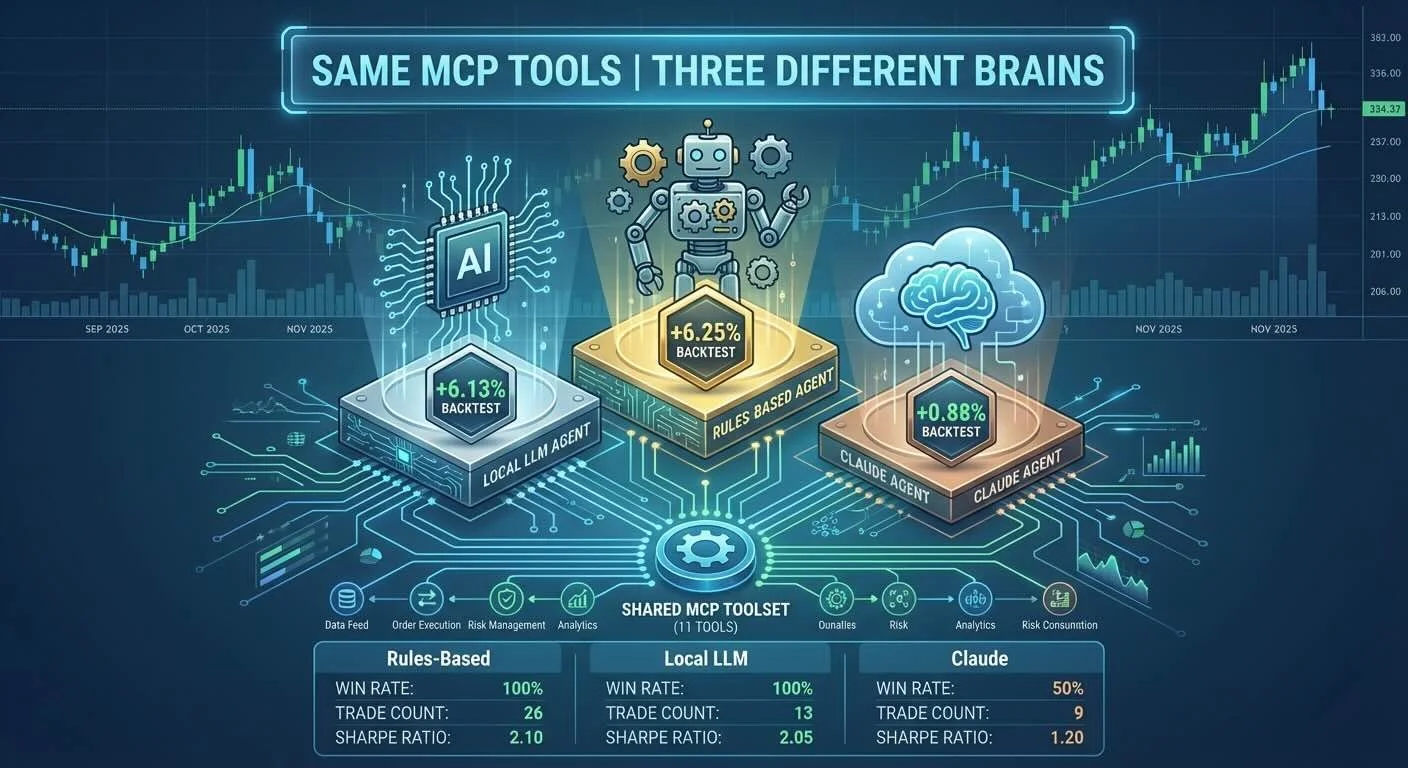
Building an MCP Agentic Stock Trading System - Part 5: Backtesting All Three Agents
I ran all three agents over 2 months of real market data to see how MCP handles different "brains" with the same tools. The results surprised me—but not in the way I expected.