
Building an MCP Agentic Stock Trading System - Part 5: Backtesting All Three Agents
This is Part 5 of a series on building an MCP trading system. Read Part 1, Part 2, Part 3, and Part 4 for the architecture, MCP servers, agentic loop, and decision comparison.
I ran all three agents over 2 months of real market data to see how MCP handles different "brains" with the same tools. The results surprised me—but not in the way I expected.
Backtest Setup:
- Period: Sep 15 - Nov 24, 2025 (50 trading days)
- Initial Capital: $100,000
- Stocks: AAPL, GOOGL, MSFT, AMZN, TSLA
- Same data, same MCP tools, three different brains
The Results:
🥇 Rules-Based: +6.25% ($106,251), 100% win rate, 26 trades, Sharpe 15.87, $0 cost
🥈 Local LLM: +6.13% ($106,129), 100% win rate, 13 trades, Sharpe 11.22, $0 cost
🥉 Claude Haiku: +0.88% ($100,875), 50% win rate, 9 trades, Sharpe 1.52, ~$0.15 cost
The surprise? Simple rules beat sophisticated AI reasoning. But the real story is how MCP let me test this hypothesis with zero architectural changes.
The rule-based agent was aggressive: 26 trades, took profits at +15%, re-entered positions, closed 90% of positions profitably. It executed a formula without second-guessing.
The Local LLM came within 0.12% of rules-based performance. Zero cost. 100% private. Reasoning transparency. It was more conservative (13 trades vs 26), held positions longer, but still achieved 100% win rate on closed positions.
Claude struggled. One bad trade (AMZN -11%) destroyed its performance. Too conservative overall (only 9 trades), but when it did trade, the reasoning looked perfect on paper. The market just disagreed.
┌─────────────────────────────────────────────────────────────────┐
│ 2-Month Backtest Results (Sep 15 - Nov 24) │
└─────────────────────────────────────────────────────────────────┘
🥇 Rules-Based 🥈 Local LLM 🥉 Claude Haiku
───────────────── ──────────────── ─────────────────
Return: +6.25% Return: +6.13% Return: +0.88%
Value: $106,251 Value: $106,129 Value: $100,875
Win Rate: 100% Win Rate: 100% Win Rate: 50%
Sharpe: 15.87 Sharpe: 11.22 Sharpe: 1.52
Drawdown: 0% Drawdown: 0% Drawdown: -2.12%
Trades: 26 Trades: 13 Trades: 9
Cost: $0 Cost: $0 Cost: ~$0.15
Strategy: Strategy: Strategy:
Aggressive Conservative Very Conservative
Takes profits Holds winners Holds too long
Re-enters Buy & hold Bad AMZN entrySame MCP tools, three different outcomes
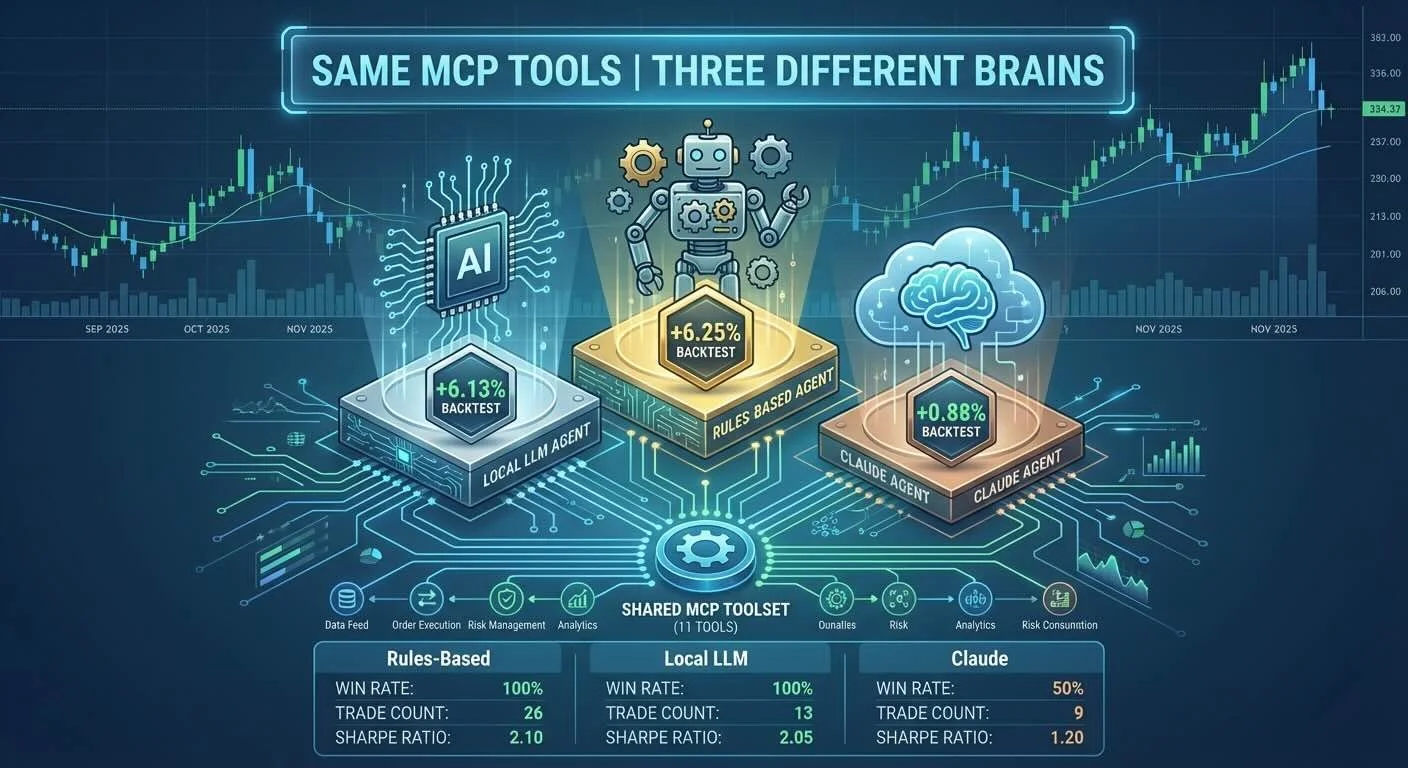
Three agents, one architecture, three different results
Full analysis: BACKTEST-COMPARISON.md
This experiment validated MCP's core promise: write tools once, test different intelligence types without rewriting anything.
The technical win isn't that rules-based performed best—it's that I could run this comparison at all. Same 11 MCP tools, three completely different decision-making approaches, identical data. One architecture, three brains.
The Local LLM result (98% of rules-based performance) proves MCP's portability claim. For zero cost and full privacy, you get near-identical results PLUS reasoning transparency. Not because the trading strategy is great—it's basic—but because the architecture supports experimentation.
Claude's underperformance doesn't invalidate cloud AI—it shows prompt engineering matters more than I expected. The MCP architecture worked perfectly (tools were called correctly, data flowed properly). The strategy needs tuning.
What other experiments could you run? Bear markets, sideways markets, longer timeframes, different stock mixes, market crashes, sector rotations. The point isn't to build a production trading system—it's to demonstrate how MCP makes this kind of comparative testing trivial. That's the real experiment here.
agentic-stock-trader - View on GitHub
This post is part of my daily AI journey blog at Mosaic Mesh AI. Building in public, learning in public, sharing the messy middle of AI development.